暂无数据
使用孤立森林进行网络流量异常检测
原标题:Web Traffic Anomaly Detection Using Isolation Forest
5 分
关键词
摘要
随着公司越来越多地进行数字化转型,其数据资产的价值也在上升,使其成为黑客更具吸引力的目标。大量的网络日志需要使用先进的分类方法,以便网络安全专家能够识别网络流量异常。本研究旨在实施孤立森林(Isolation Forest),一种无监督的机器学习方法,用于识别异常和非异常的网络流量。来自一个电子商务网站的公开网络日志数据集经过了一系列系统化的数据准备过程,包括数据摄取、数据类型转换、数据清理和标准化。这导致在训练集中添加了派生列,并在手动标记的测试集中使用,以比较孤立森林模型与网络安全专家的异常检测性能。开发的孤立森林模型使用Python的Scikit-learn库实现,表现出93%的准确率、95%的精确率、90%的召回率和92%的F1分数。通过适当的数据准备、模型开发、模型实施和模型评估,本研究表明孤立森林可以成为接近准确的网络流量异常检测的可行解决方案。
AI理解论文
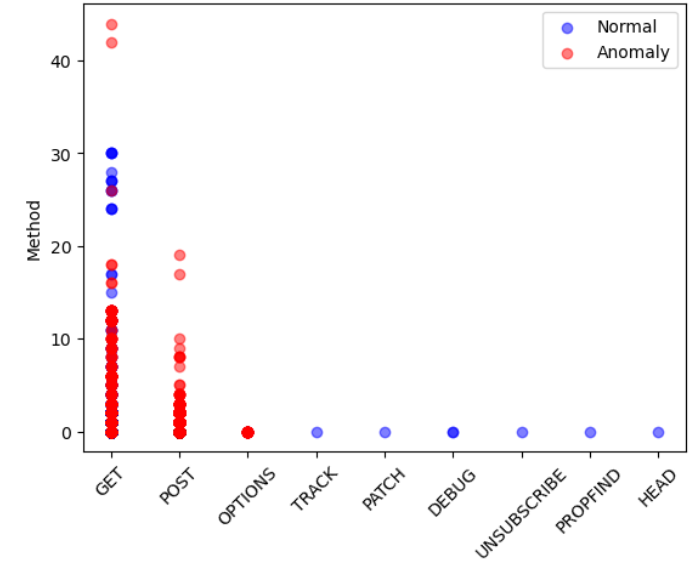
该文档主要探讨了Isolation Forest模型在检测网络流量异常中的应用,特别是在处理不平衡数据集时的表现。研究的核心在于通过多种特征的生成和分析,增强对Isolation Forest模型性能和行为的理解。
数据准备与处理
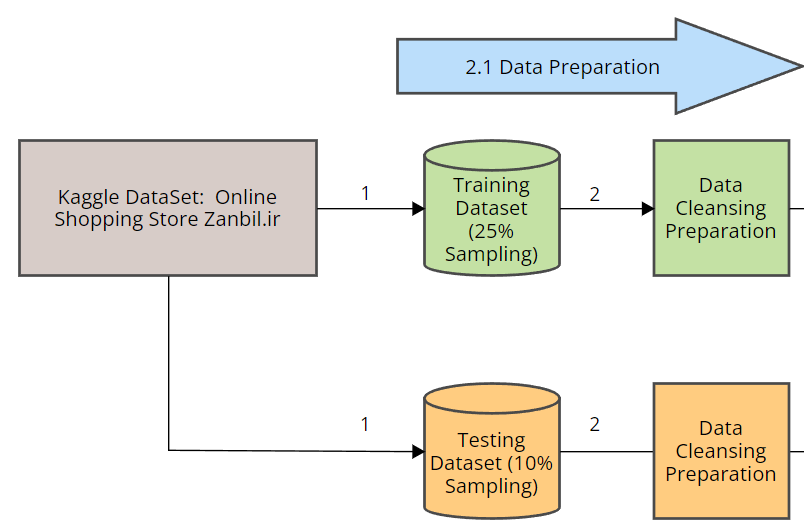
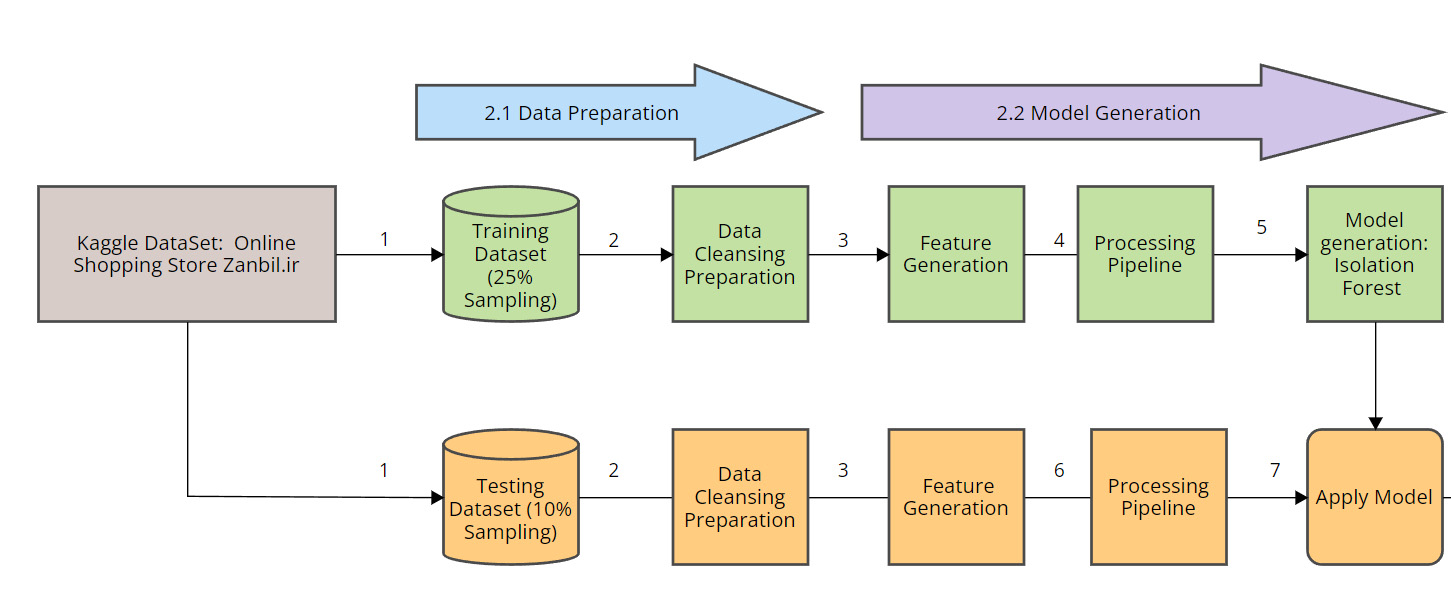
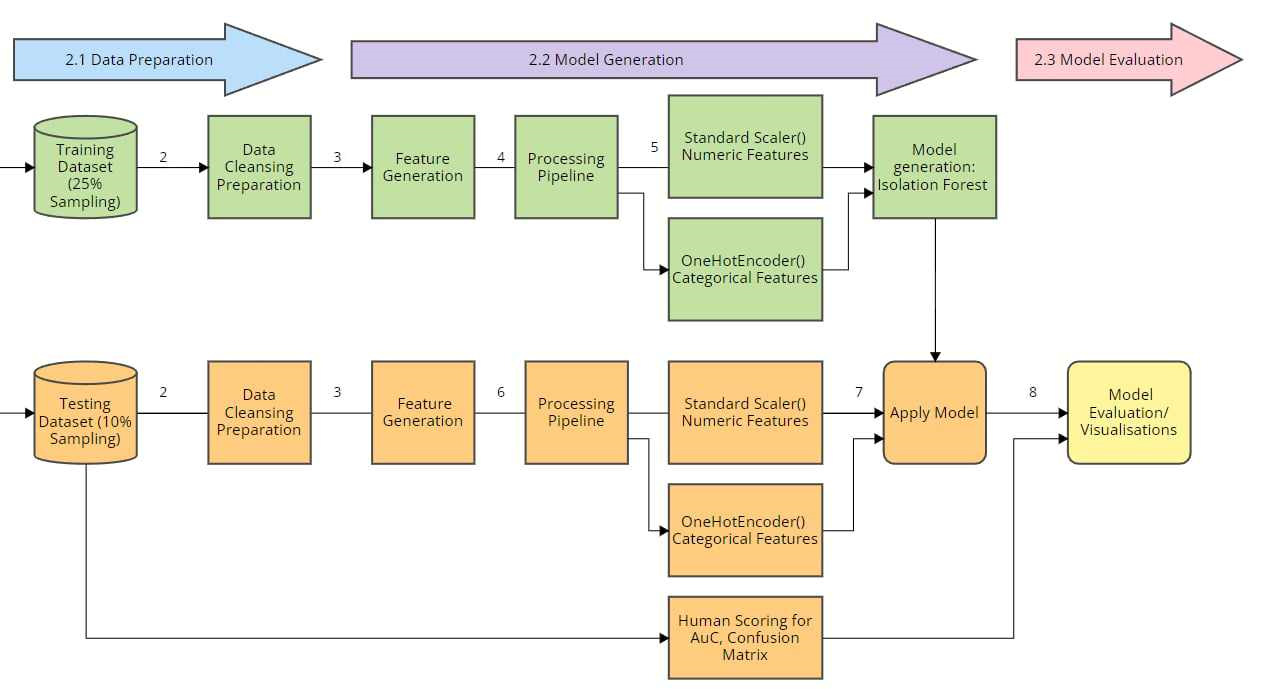
研究使用了2019年在线购物商店的Web服务器日志数据集,数据集来自Harvard Dataverse,包含约1000万行的Nginx服务器访问日志。数据准备阶段包括数据的摄取、数据类型转换和数据清洗。研究者从数据集中抽取了25%的日志作为训练数据集,并删除了任何缺失数据的行。为了减少swamping(正常数据点被错误标记为异常)和masking(实际异常被错误标记为正常)的现象,研究者选择了较小的样本量进行训练。
特征生成
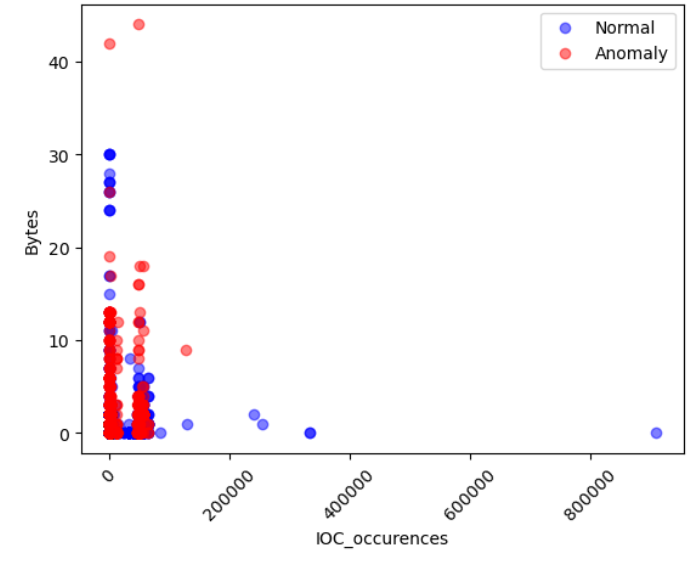
在特征生成阶段,研究者从URI、User-Agent和Referrer列中提取了新的特征,包括URI_occurences、IOC_occurences、User-Agent_occurences、URI_length和UserAgentLength。这些特征用于检测异常字符集和**IoC(Indicators of Compromise)**的出现。IoC是指可能表明系统受到威胁的特征或模式,通常在合法的User-Agent字符串中不存在。
模型实现与评估
Isolation Forest模型作为一种无监督机器学习模型,通过随机分区的方式创建Isolation Trees,以识别数据集中显著偏离预期行为的数据点。研究者在模型评估阶段,使用了准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1-score等多种指标来评估模型的性能。虽然准确率是一个重要的指标,但在不平衡数据集中可能会高估模型的性能,因此需要结合其他指标进行全面评估。
- 准确率(Accuracy):衡量模型整体预测的正确性。
- 精确率(Precision):计算模型预测的正类中真正为正的比例。
- 召回率(Recall):衡量模型识别出所有实际正类实例的能力。
- F1-score:精确率和召回率的调和平均数,用于综合评估模型性能。
结果与贡献
研究结果表明,Isolation Forest模型在识别网络流量异常方面表现出色,尤其是在减少**假阳性(False Positives)和假阴性(False Negatives)**方面。通过生成和分析多种特征,研究者能够更好地理解模型的行为,并提高其检测潜在威胁的能力。研究强调了在不平衡数据集中使用多种评估指标的重要性,以避免对模型性能的偏见。
结论
该研究通过系统的数据准备、特征生成和模型评估流程,展示了Isolation Forest模型在网络流量异常检测中的有效性。研究不仅提供了对模型性能的深入理解,还为未来在类似领域的应用提供了参考框架。通过结合多种评估指标,研究者能够全面评估模型的分类性能,确保在不平衡数据集中也能准确识别异常。
总之,该文档为Isolation Forest模型在网络流量异常检测中的应用提供了详细的分析和评估,强调了数据准备和特征生成的重要性,并通过多种评估指标全面评估了模型的性能。