暂无数据
数据驱动的单变量全脑关联研究可重复性估计中的偏差
原标题:Bias in data-driven estimates of the replicability of univariate brain-wide association studies
5 分
关键词
摘要
最近的研究使用大型神经影像数据集来回答一个重要问题:进行可重复的全脑关联研究需要多少受试者?这些数据驱动的方法可以被视为测试几种神经影像模型和测量的可重复性的框架。在这里,我们测试了该框架的一部分,即通过替换重采样大型数据集获得的单变量脑-行为关联的统计误差估计。我们证明,报告的统计误差估计在很大程度上是由于在接近完整样本量时替换采样引入的随机效应偏差。我们表明,未来的荟萃分析可以通过仅重采样到完整样本量的10%来大幅避免这些偏差。我们讨论了再现大规模单变量关联研究需要成千上万名参与者的影响,敦促研究人员采用其他方法学方法。
AI理解论文
该文档主要探讨了在大规模数据集上进行重采样时,单变量脑-行为关联研究(BWAS)统计误差估计的偏差问题。研究者们通过模拟实验验证了Marek, Tervo-Clemmens等人提出的框架,并指出在接近完整样本量进行重采样时,统计误差估计会受到随机效应的偏倚影响。以下是该文档的主要内容:
研究背景与目的
背景:Marek, Tervo-Clemmens等人利用大型神经影像数据集,研究了进行可重复的脑-行为关联研究所需的样本量。他们的方法被视为测试多种神经影像模型和测量的可重复性框架。
目的:本文旨在检验Marek, Tervo-Clemmens等人框架中单变量脑-行为关联统计误差估计的有效性,特别是通过重采样大数据集的方法。
方法
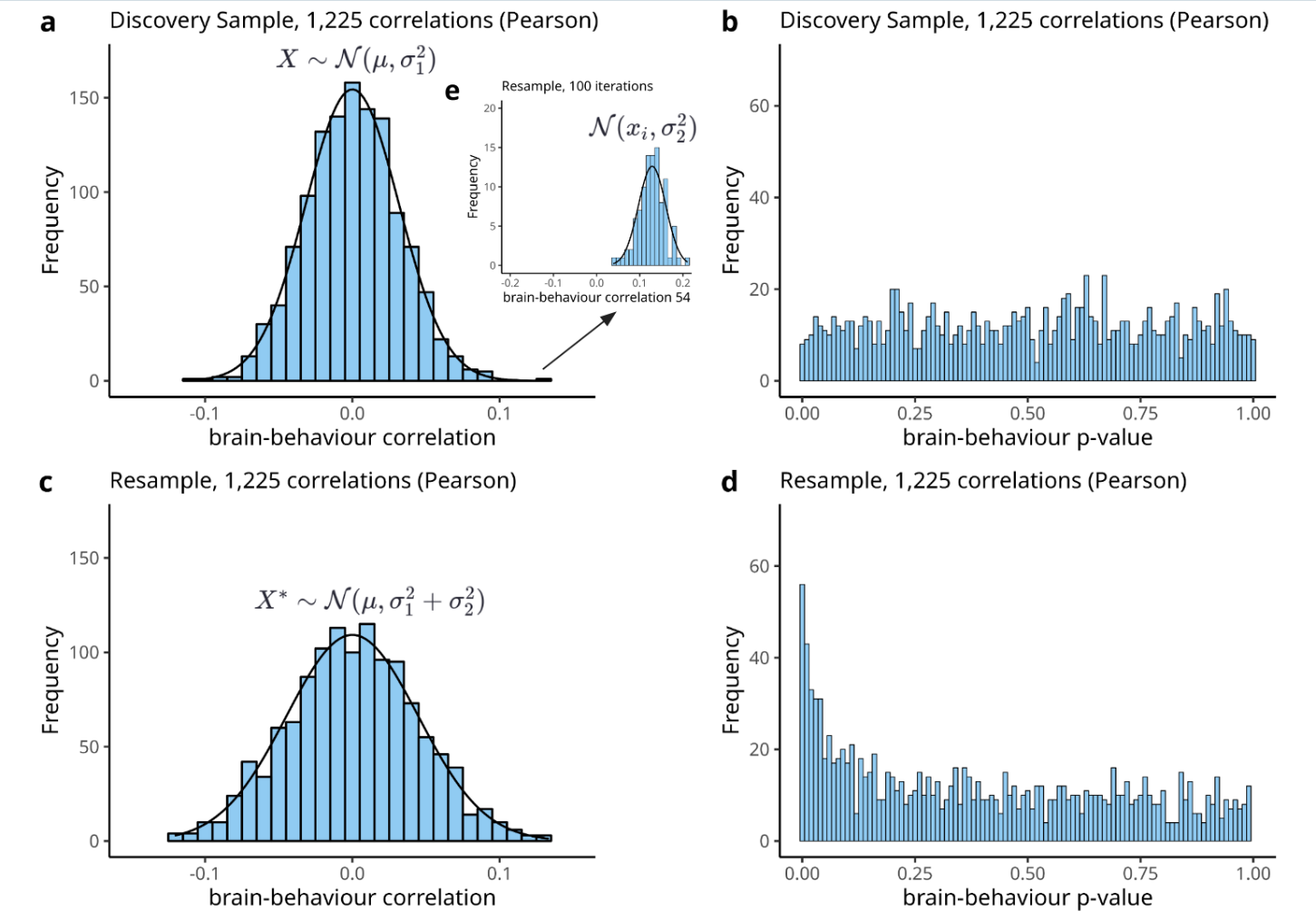
模拟实验设计:研究者模拟了一个发现样本(n = 1,000),其中包含1,225个脑连接测量(随机Pearson相关)和一个行为测量(在参与者中正态分布)。通过将每个脑连接测量与行为进行相关分析,获得1,225个脑-行为相关。
重采样方法:研究者从发现样本中进行重采样,样本量从25到1,000不等,并估计统计误差。这一过程重复100次,以验证Marek, Tervo-Clemmens等人方法的有效性。
结果
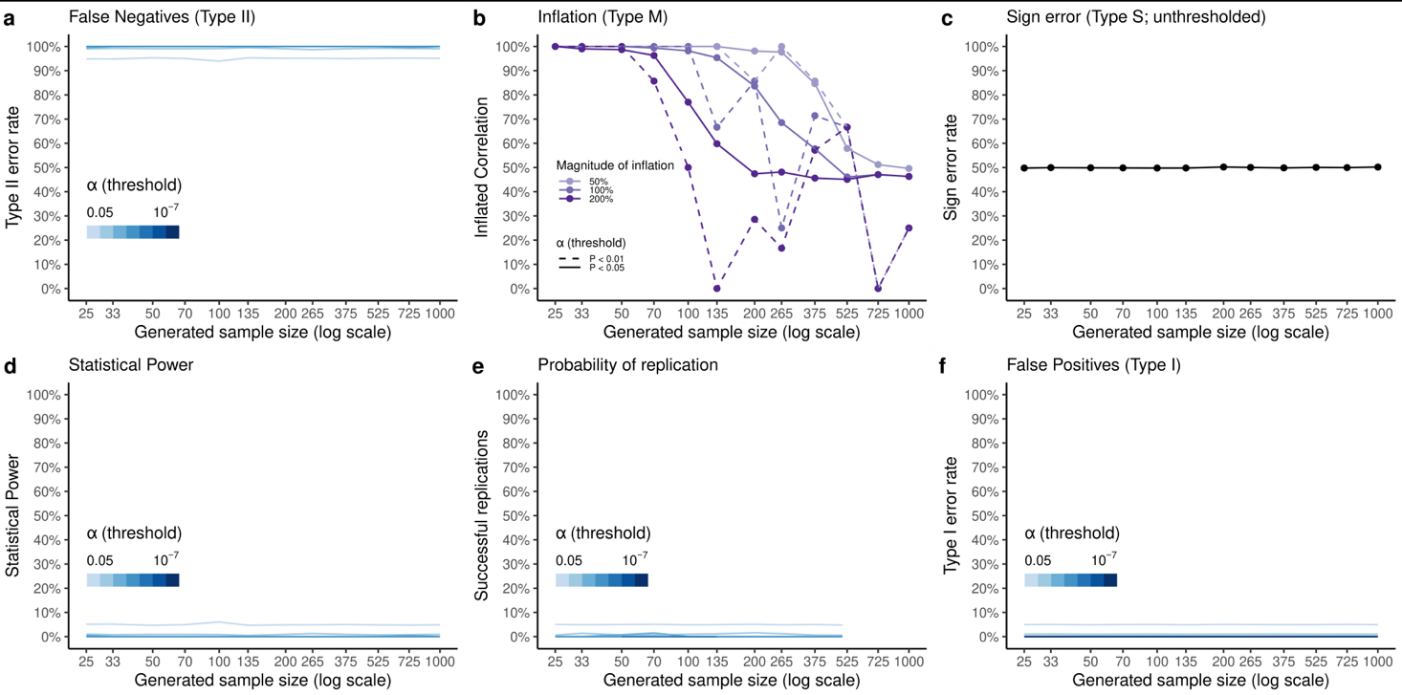
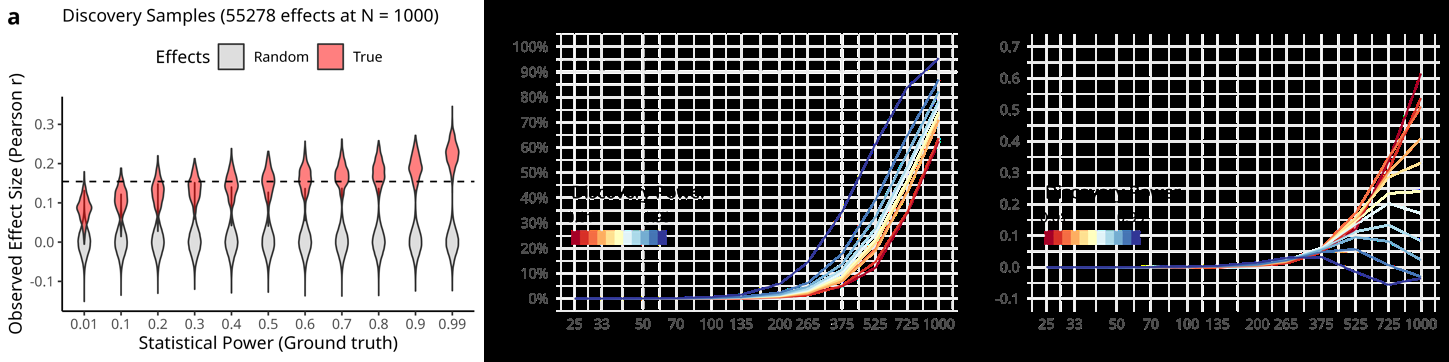
偏倚的发现:研究者发现,即使在随机数据下,统计误差和可重复性趋势与Marek, Tervo-Clemmens等人报告的结果相似,显示出强烈的统计功效估计偏倚。
偏倚来源:偏倚主要来源于重采样接近完整样本量时的随机效应。具体表现为:
- 功效膨胀:在发现样本的尾部,随机相关更可能在重采样的复制样本中再次显著。
- 分布扩展:重采样导致相关分布比预期更宽,增加了极端尾部的概率,从而膨胀了接近0的P值。
讨论
偏倚的影响:这种偏倚在无真实效应的情况下尤为明显,但在存在真实效应时也可能存在。研究者强调,统计功效在发现样本功效低时被膨胀,而在功效高时略微被压缩。
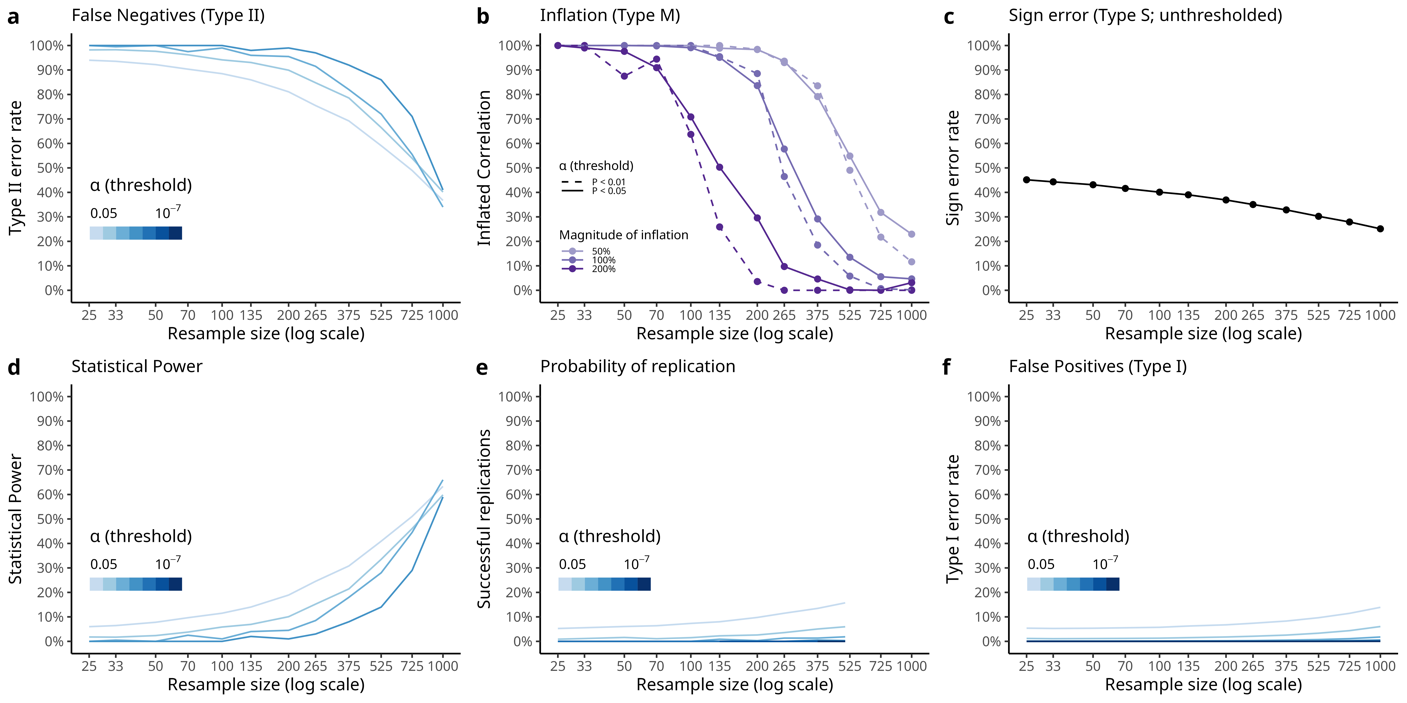
方法论建议:研究者建议在进行重采样时,仅限于完整样本量的10%以内,以避免偏倚。这一方法在Marek, Tervo-Clemmens等人的UK Biobank结果中被验证,显示出单变量BWAS即使在数千个个体中也不具可重复性。
结论
研究者总结道,单变量BWAS的统计误差估计在接近完整样本量进行重采样时存在方法论偏倚。为了提高研究的可重复性,研究设计和模型选择至关重要。未来的研究应考虑本文讨论的方法论因素,以获得更准确的统计误差估计。
专业术语解释
- 单变量脑-行为关联研究(BWAS):研究单一变量(如脑连接测量)与行为之间的关联。
- 重采样:从一个样本中随机抽取子样本进行分析,以估计统计误差。
- 统计功效:检测到真实效应的能力,通常与样本量和效应大小有关。
- 偏倚:统计估计偏离真实值的系统性误差。
通过本文的研究,研究者揭示了在大规模数据集上进行重采样时可能出现的统计误差偏倚问题,并提出了避免这些偏倚的方法建议。这为未来的脑-行为关联研究提供了重要的参考。