暂无数据
使用交互式视觉-语言系统的自我中心行走环境感知
原标题:Egocentric Perception of Walking Environments using an Interactive Vision-Language System
5 分
关键词
摘要
大型语言模型可以提供比单纯计算机视觉更详细的场景上下文理解,这对机器人技术和具身智能有重要意义。在这项研究中,我们开发了一种新颖的多模态视觉语言系统,用于自我中心的视觉感知,初步重点放在现实世界的步行环境上。我们在自定义的数据集上训练了一些基于最新技术的变压器视觉语言模型,该数据集包含43,055对图像文本,用于少样本图像描述生成。然后,我们设计了一个新的语音合成模型和用户界面,将生成的图像描述转换为语音,以便为用户提供音频反馈。我们的系统还独特地允许前馈用户提示,以个性化生成的图像描述。我们的系统能够生成平均长度为10个单词的详细描述,同时实现了43.9%的高ROUGE-L得分和28.1%的低词错误率,端到端处理时间为2.2秒。总体而言,我们的新多模态视觉语言系统能够生成准确且详细的自然场景描述,并且可以通过用户提示进一步增强。这一创新功能使我们的图像描述能够根据用户的个体和即时需求与偏好进行个性化,从而优化人类与生成式AI模型之间在理解和导航现实世界环境中的闭环互动。
AI理解论文
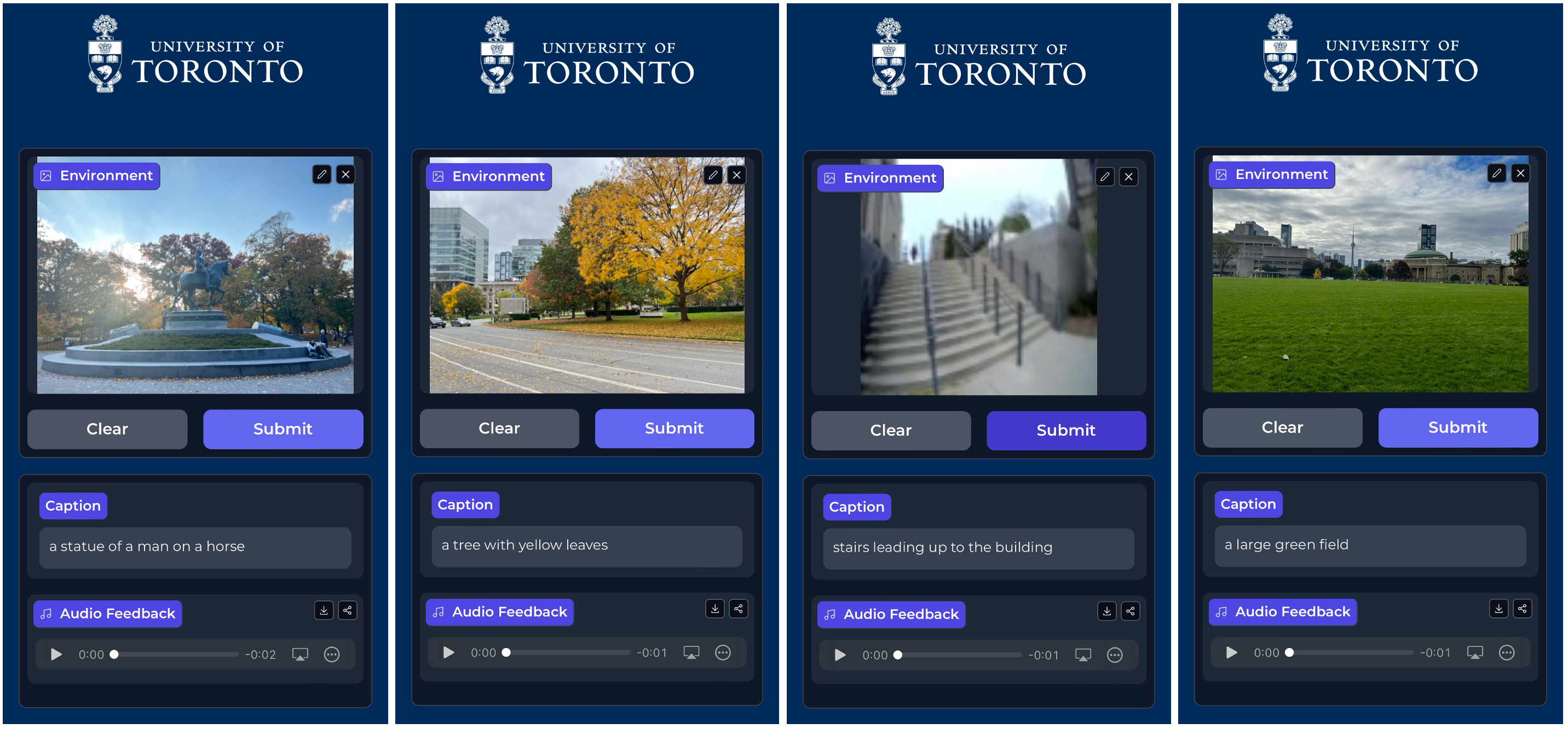
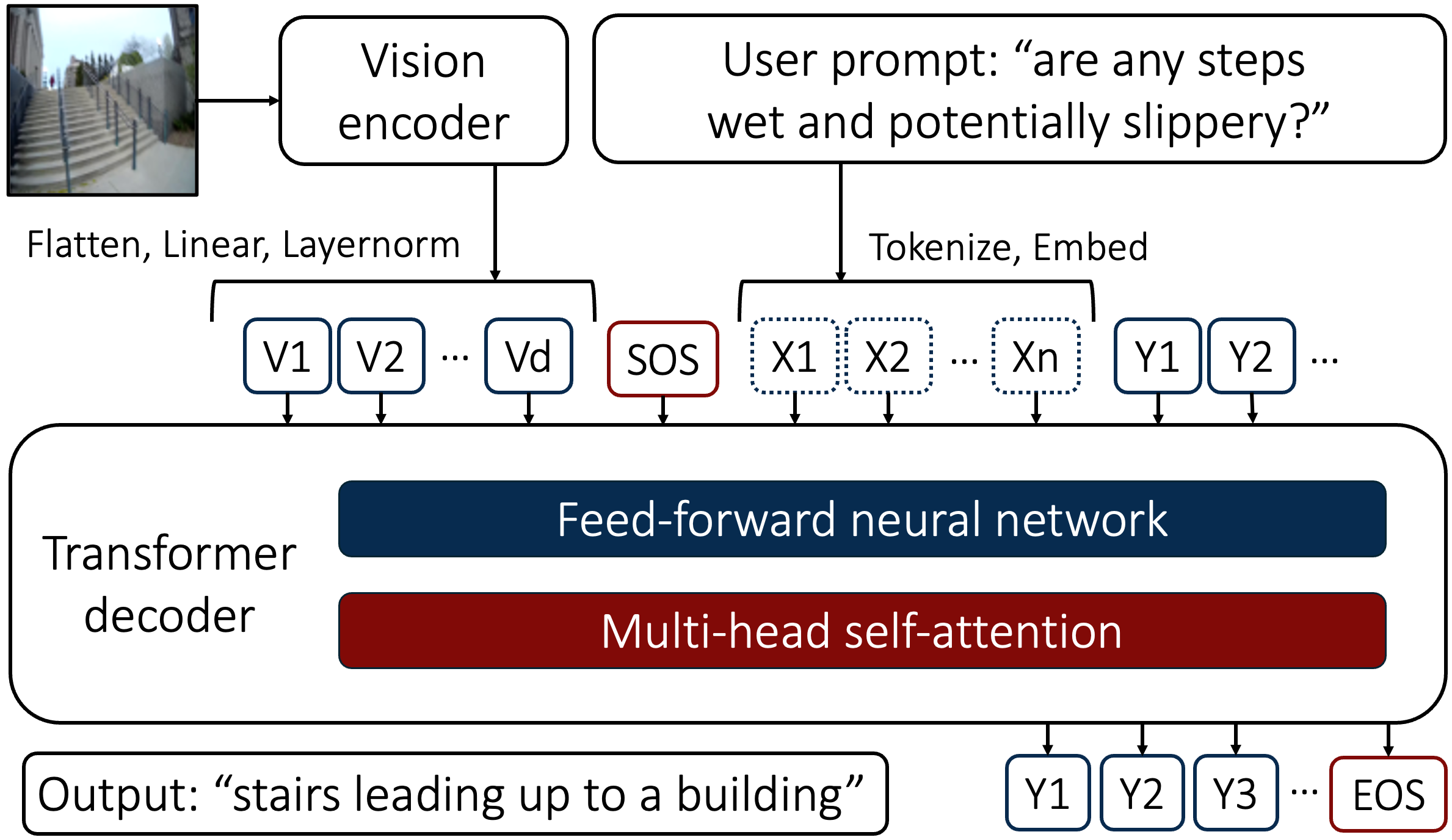
该文档介绍了一种新型多模态视觉语言系统,旨在增强对真实世界行走环境的自我中心视觉感知。研究的核心是开发一种能够生成详细图像描述的系统,并将这些描述转换为语音反馈,以便用户能够通过音频与系统交互。以下是该论文的主要内容和贡献:
引言
视觉在人类运动中起着关键作用,通过提供环境反馈帮助个体导航障碍物、保持平衡并相应调整行为。该研究受到生物视觉运动控制的启发,结合了计算机视觉和自然语言处理,以提供更详细的场景上下文理解。
数据集
研究使用了一个包含43,055对图像-文本的自定义数据集,平均每个描述长度为10-15个词。数据集的构建基于关键词的出现,并进行了标准化处理和随机分割,90%用于训练,10%用于测试。
模型架构
系统采用编码器-解码器框架,这是当前视觉语言模型的常见结构。视觉编码器将图像转换为视觉标记序列,文本解码器则生成与视觉环境相关的上下文描述。为了提高文本生成质量,研究应用了基于Transformer的因果语言建模,这种模型能够通过注意力机制捕捉广泛的上下文。
- 视觉编码器:使用了Vision Transformer (ViT) 模型,将图像分割为编码块。
- 文本解码器:使用了GPT2模型,能够解释视觉嵌入并生成描述性标题。
模型训练
研究在NVIDIA Tesla A100 GPU上对模型进行了微调,使用16位浮点精度以减少GPU内存需求并加速训练。微调后的模型在生成图像标题时表现出色,ROUGE-L得分为43.9%,词错误率为28.1%。
语音合成模型
为了将生成的图像标题转换为语音,研究开发了一种基于SpeechT5 Transformer的语音合成模型。该模型能够将文本嵌入映射为语音输出,并通过**生成对抗网络(GAN)**生成高质量的语音波形。
用户界面设计
系统部署在Gradio平台上,并嵌入到基于Next.js框架的网页应用中,强调人机交互和简约的用户界面设计,以提高可访问性。
性能评估
研究通过ROUGE和**词错误率(WER)**等指标对模型性能进行了评估。ROUGE得分用于衡量生成文本与参考文本的相似性,而WER则衡量生成文本与参考文本之间的替换、删除和插入错误。
结果与讨论
研究结果表明,ViT-GPT2模型在MSCOCO数据集上取得了高ROUGE-1得分48.3%,ROUGE-2得分21.8%,ROUGE-L得分43.9%。GIT模型的词错误率为28.1%。在处理速度方面,文本反馈生成最快,结合音频反馈略微增加了处理时间,而用户提示显著增加了处理时间。
贡献与未来工作
该研究的创新之处在于允许用户通过前馈用户提示个性化生成的图像标题,从而优化人机交互。未来的研究可以通过优化模型以减少计算需求,探索边缘计算以降低延迟,以及添加自动语音识别模型来进一步提高系统效率。
总之,该研究开发了一种新型的多模态交互视觉语言系统,能够生成准确详细的场景描述,并通过用户提示进行个性化调整。这一系统在机器人技术、具身智能和人机交互领域具有重要的应用潜力。