暂无数据
使用时间序列聚类方法进行能源行业股票价格预测
原标题:Energy Sector Stock Price Forecasting with Time Series Clustering Approach
5 分
关键词
摘要
股票投资承诺更高的回报,但由于价格波动不可预测,风险也很高。能源行业在2022年显示出潜力,因为其行业指数增长最高。然而,这并不意味着所有发行人的股票价格都会均匀上涨。因此,有必要根据股票价格走势的相似性对发行人进行聚类分析,并用于在聚类层面预测股票价格。本研究旨在评估使用基于自相关的距离和动态时间规整(DTW)对能源行业发行人进行聚类的表现,并在聚类层面预测股票价格。所用数据包括每周的股票收盘价。聚类采用层次平均连接法。每个聚类的股票价格预测使用ARIMA模型,其表现通过滚动交叉验证进行评估。结果表明,DTW距离具有最佳的聚类表现。能源行业发行人被分为四个聚类,具有强聚类类别,表明轮廓系数>0.71。每个聚类的ARIMA模型产生的MAPE值在10-20%之间,将其归类为良好的预测模型。建议投资者关注A和D聚类,因为根据预测的股票价格,它们具有最高的资本增值潜力。这些聚类还包括具有强劲基本面和股息政策的公司。
AI理解论文
这篇论文题为“Energy Sector Stock Price Forecasting with Time Series Clustering Approach”,发表在《Indonesian Journal of Statistics and Its Applications》上,主要探讨了通过时间序列聚类方法对能源行业股票价格进行预测的研究。以下是对该论文的详细总结:
引言
论文首先指出股票投资的高回报和高风险特性,尤其是由于价格波动难以预测。能源行业在2022年表现出显著的潜力,成为增长最快的行业之一。然而,这种增长并不均匀分布于所有发行人。因此,研究的重点是基于股票价格走势的相似性对发行人进行聚类,并在聚类层面进行股票价格预测。
研究目标
该研究旨在评估使用自相关距离(autocorrelation-based distance)和动态时间规整(Dynamic Time Warping, DTW)进行能源行业发行人聚类的性能,并在聚类层面预测股票价格。研究使用了每周的股票收盘价数据,采用层次平均链接法(hierarchical average linkage method)进行聚类。每个聚类的股票价格预测使用ARIMA模型,并通过滚动交叉验证(rolling-cross validation)评估其性能。
方法论
-
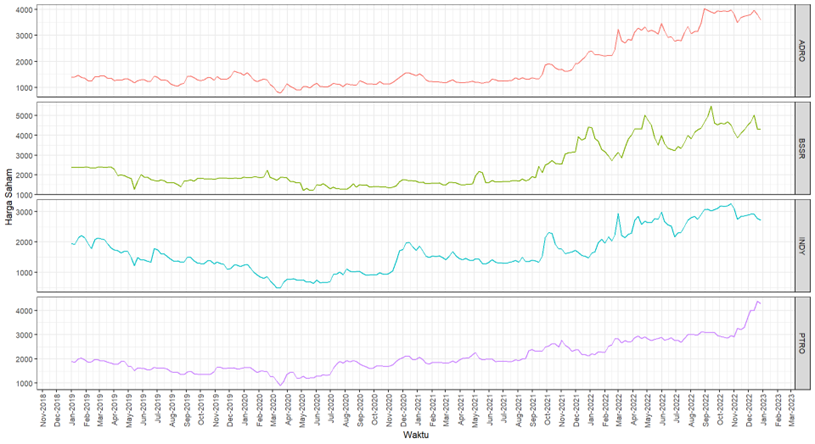
数据来源与预处理:研究使用了从印尼证券交易所和雅虎财经获取的二级数据,涵盖2019年1月1日至2022年12月30日期间的能源行业股票周收盘价。数据预处理包括筛选符合特定标准的发行人,如排除2019年及之后IPO的股票。
-
聚类分析:
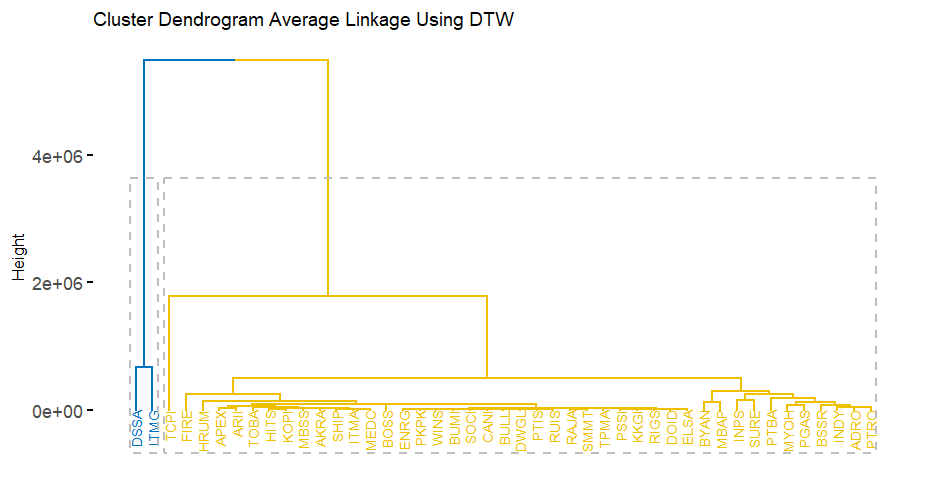
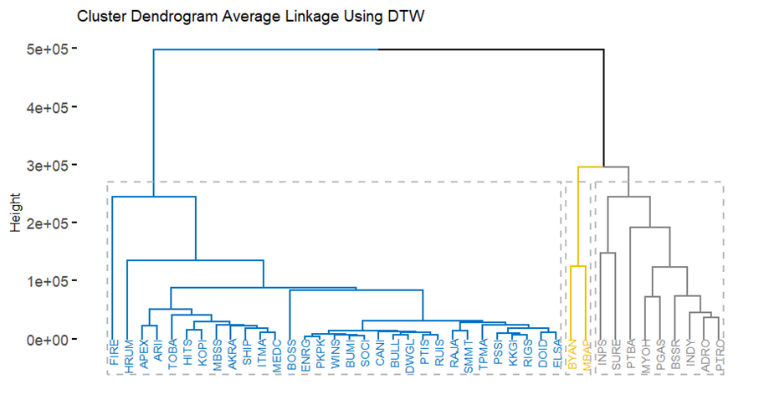
- 时间序列聚类:由于时间序列数据的高维特性和特征相关性,采用层次聚类方法。DTW距离被证明在处理时间序列数据时优于欧几里得距离,因为它不仅考虑数值接近性,还考虑模式和数据移动的相似性。
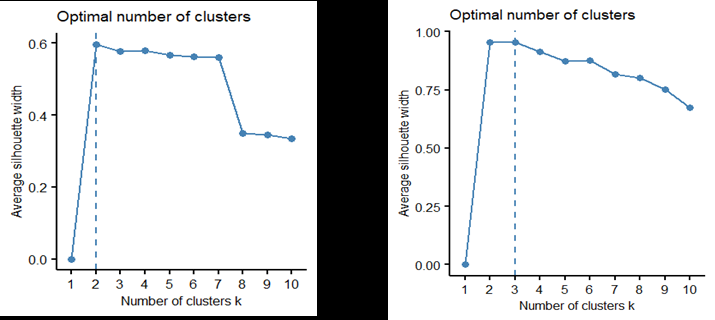
- 聚类评估:通过**轮廓系数(silhouette coefficient)**评估聚类质量,结果显示DTW距离的聚类性能最佳,形成了四个聚类,且轮廓系数大于0.71,表明聚类质量较高。
-
模型构建与预测:
- ARIMA模型:在每个聚类层面使用ARIMA模型进行预测。模型选择基于最小的AIC值和参数显著性。
- 模型评估:通过滚动交叉验证计算平均绝对百分比误差(MAPE),MAPE值在10-20%之间,表明预测模型性能良好。
结果与讨论
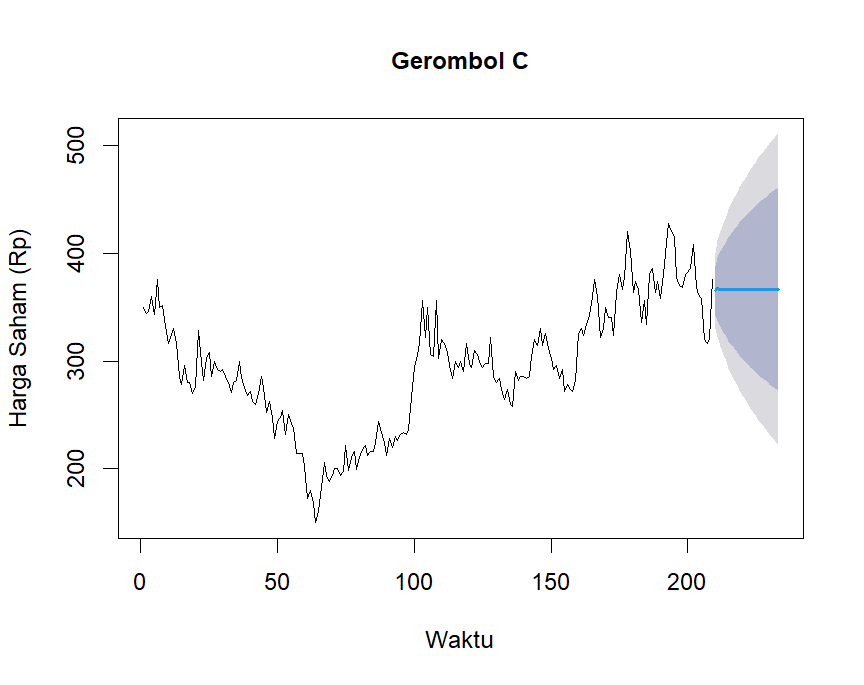
研究结果显示,能源行业的发行人被分为四个聚类,每个聚类的股票价格表现和模式不同:
- 聚类A:包含高价股票,长期趋势上升,流动性好,潜在收益高。
- 聚类B:中等价位股票,价格围绕平均值波动,疫情前后表现出不同的趋势。
- 聚类C:低价股票,价格波动低于平均值。
- 聚类D:包含两个发行人,价格波动模式独特,2022年表现出上升趋势。
结论
论文建议投资者关注聚类A和D,因为这些聚类的公司具有强劲的基本面和股息政策,预示着较高的资本增值潜力。研究表明,通过聚类分析进行股票价格预测可以提高预测效率,为投资者提供更有价值的决策信息。
术语解释
- 动态时间规整(DTW):一种用于计算时间序列之间相似性的算法,能够处理时间轴上的非线性变形。
- ARIMA模型:自回归积分滑动平均模型,是一种用于时间序列分析的统计模型,结合了自回归和移动平均成分。
- 轮廓系数(silhouette coefficient):用于评估聚类质量的指标,值越高表示聚类效果越好。
这篇论文通过结合时间序列聚类和ARIMA模型,为能源行业股票价格预测提供了一种创新的方法,具有重要的实用价值和理论贡献。