暂无数据
Mera:通过冗余探索实现量子电路模拟的内存减少和加速
原标题:Mera: Memory Reduction and Acceleration for Quantum Circuit Simulation via Redundancy Exploration
5 分
关键词
摘要
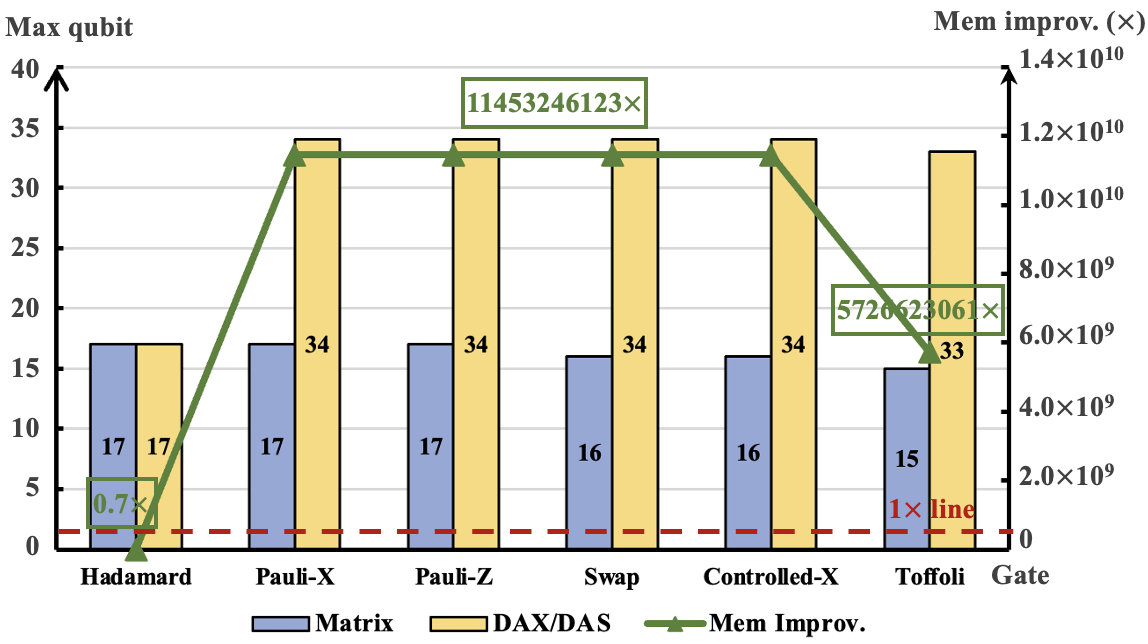
随着量子计算的发展,量子处理器在特定应用中展示了潜在的优势,例如Grover的数据库搜索和流行的量子神经网络(QNNs)。为了更好地校准量子算法和机器,在经典计算机上进行量子电路模拟变得至关重要。然而,随着量子比特(qubits)数量的增加,内存需求呈指数增长。为了减少内存使用并加速模拟,我们提出了一种多级优化方法,即Mera,通过探索内存和计算冗余。首先,对于大量稀疏量子门,我们提出了两种用于低级全状态模拟的压缩结构。相应的门操作被设计用于实际实现,从而避免了长时间的压缩和解压缩。其次,对于用于构建叠加态的密集Hadamard门,我们设计了一种定制结构,以作为面向规则的模拟显著节省内存。同时,按需振幅更新过程经过优化以加速执行。实验表明,我们的压缩结构将量子比特的数量从17增加到35,并在QNN中实现了高达6.9倍的加速。
AI理解论文
该文档主要探讨了量子电路模拟中的内存需求和计算加速问题,并提出了一种名为Mera的多级优化方法,通过探索冗余来减少内存使用和加速模拟。以下是对该论文的详细总结:
引言
随着量子计算的发展,量子处理器在特定应用中展示了潜在的优势,如Grover数据库搜索和量子神经网络(QNNs)。然而,由于现有物理量子处理器的不成熟和高开销,在经典计算机上进行量子电路模拟变得至关重要。随着量子比特(qubits)数量的增加,内存需求呈指数增长,成为模拟的瓶颈。
研究背景
量子电路模拟依赖于矩阵张量积(MTP)操作,这导致操作矩阵和状态向量的内存需求呈指数增长。一个n量子比特电路在每个时间步产生一个大小为2^n×2^n的操作矩阵和一个大小为2^n的状态向量。由于每个元素用双精度复数表示,内存需求迅速增加。
相关工作
现有的研究主要依赖于超级计算机来缓解内存瓶颈,但即便是超级计算机也存在内存上限。此外,超级计算机的硬件和软件平台不易访问。其他研究则专注于编译级优化和分布式系统中的并行计算,但仍存在大量内存和计算冗余。
方法
论文提出了一种名为Mera的多级优化方法,通过探索冗余来减少内存使用和加速模拟。具体方法包括:
-
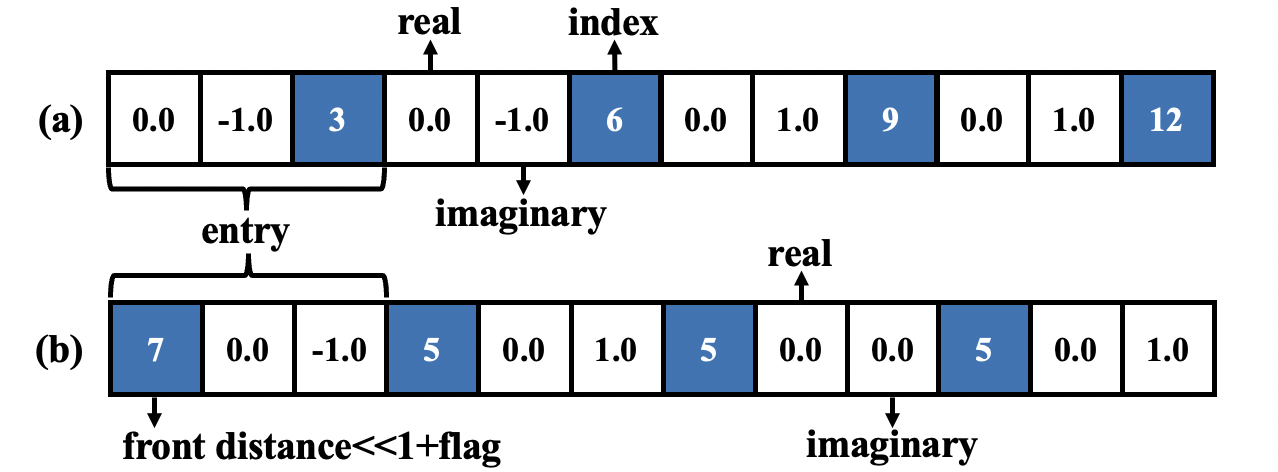
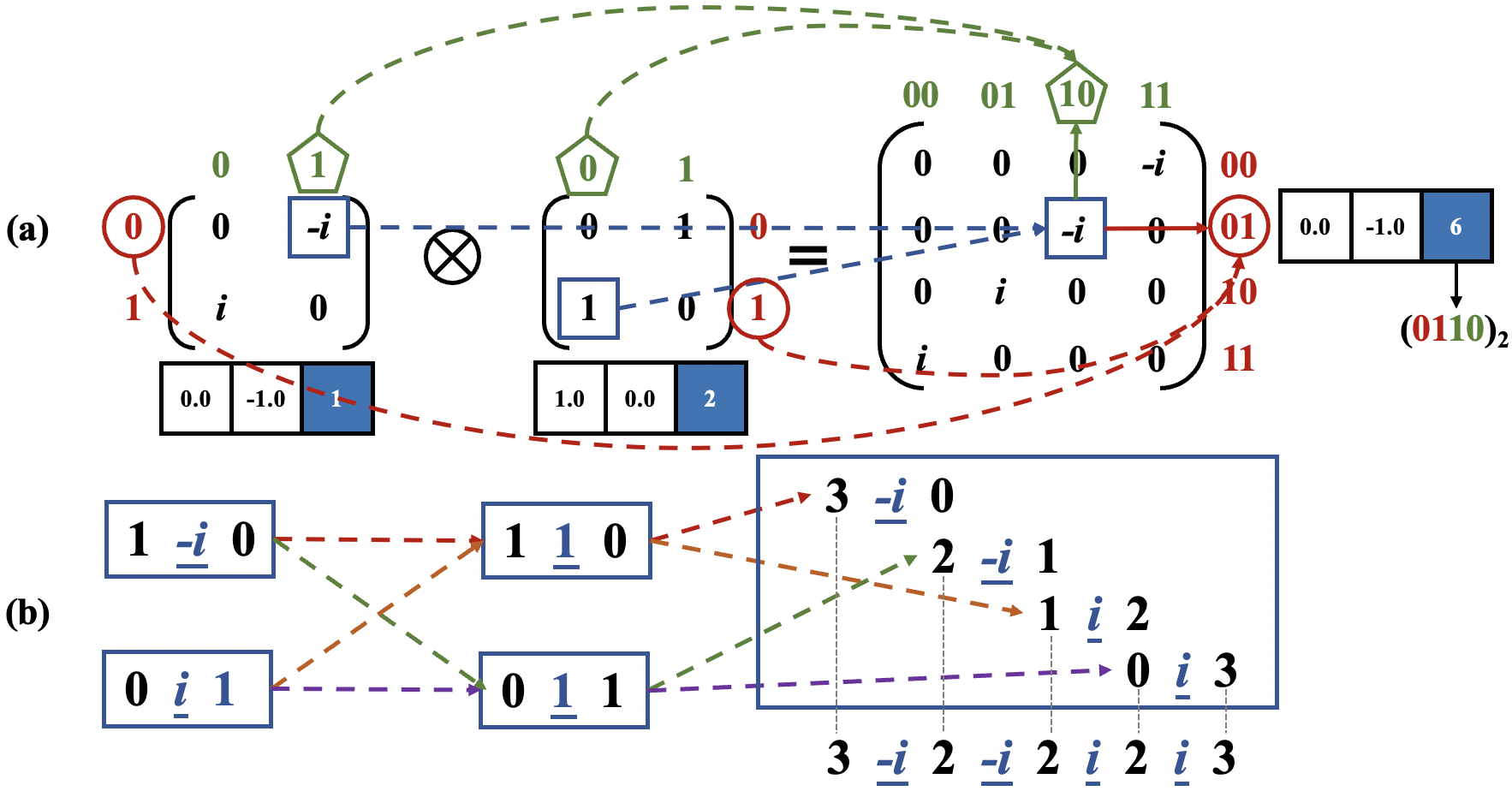
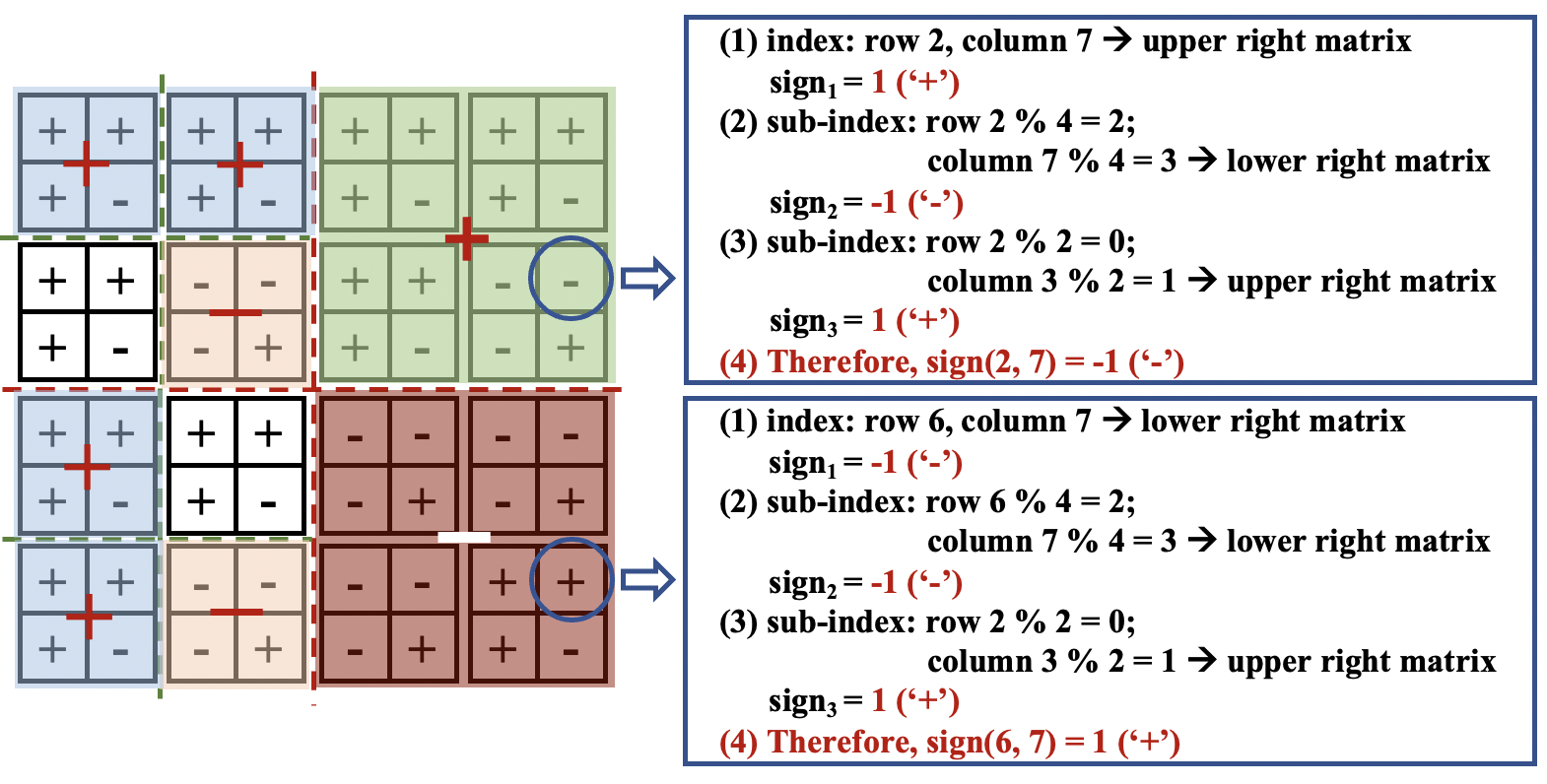
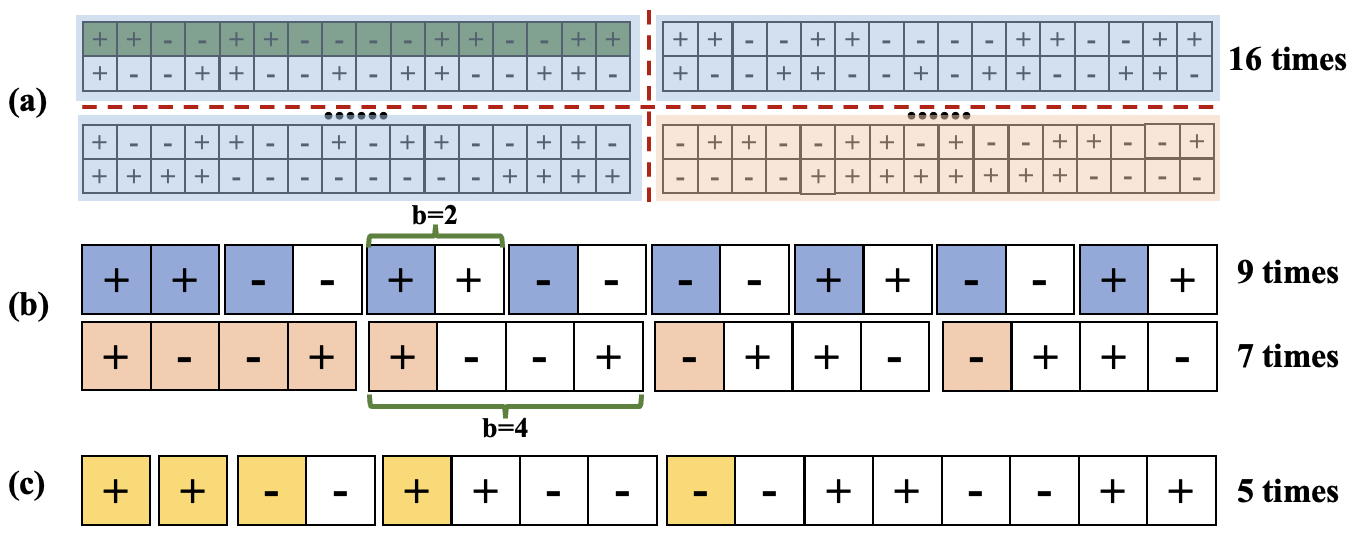
稀疏量子门的压缩结构:针对大量稀疏量子门,设计了两种新的压缩结构(DAX和DAS),用于低级全状态模拟。这些结构通过编码量子门并设计相应的MTP和矩阵-向量乘法(MVM)计算,避免了长时间的压缩和解压缩过程。
-
密集Hadamard门的定制结构:由于Hadamard门是构建量子叠加态的关键,其矩阵没有零元素,因此无法压缩。论文设计了一种新的定制结构用于规则导向的模拟,并优化了相应的MVM操作以提高模拟效率。
实验结果
实验表明,压缩结构可以将量子比特数量从17增加到34,并在MTP和MVM操作中分别实现了高达1800.3倍和141.2倍的加速。对于密集的Hadamard门,方法在QNN和Grover算法中实现了高达6.9倍和4.6倍的模拟加速。
贡献
论文的主要贡献包括:
- 探索量子门的稀疏性,提出两种新的压缩结构用于低级模拟,并通过放弃长时间的压缩和解压缩来加速MTP和MVM操作。
- 针对密集Hadamard门的计算冗余,设计了一种新的定制结构用于规则导向的模拟,并通过按需解析结构优化MVM计算。
- 实验结果验证了方法的有效性,显著提高了量子电路模拟的内存效率和计算速度。
结论
该研究通过探索量子门的稀疏性和计算冗余,提出了一种有效的内存减少和加速模拟的方法,为量子电路模拟提供了新的思路和技术支持。这种方法不仅在理论上具有创新性,也在实践中展示了显著的性能提升。
通过以上总结,读者可以全面理解论文的内容、方法和贡献,尤其是其在量子电路模拟中的实际应用价值。