暂无数据
ODSBAHIA-PTBR:支持可持续发展目标的自然语言处理模型
原标题:ODSBAHIA-PTBR: A Natural Language Processing Model to Support Sustainable Development Goals
5 分
关键词
摘要
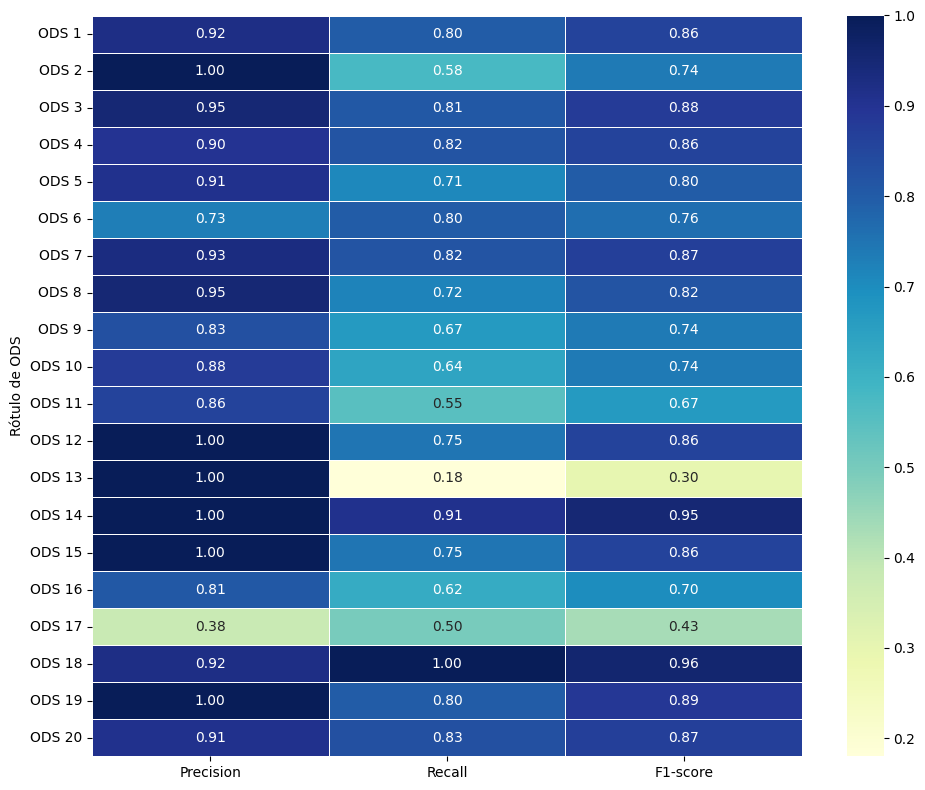
目标:本研究旨在提出一种方法,用于客观分类葡萄牙语文本,以与巴西2030议程的可持续发展目标(SDGs)相关联。 理论框架:该研究使用自然语言处理(NLP)技术与深度学习,采用预训练模型如BERTimbau Base、DeBERTinha和Albertina。此外,它还考虑了现有文献中关于与联合国17个可持续发展目标相关的葡萄牙语文本分类的空白,并包括在2020年由UnB和UNESP合作编写的《2030议程指南:整合可持续发展目标、教育和社会》文件中提出的三个新可持续发展目标,即SDG 18(种族平等)、SDG 19(艺术、文化和传播)和SDG 20(土著人民和传统社区的权利)。 方法:研究是探索性、描述性和应用性的,采用定量方法和实验程序。预训练模型根据专门为该任务创建的多标签数据集进行了调整。BERTimbau Base表现最佳,并被用作创建ODSBahia-PTBR模型的基础,该模型通过精确度(82%)、召回率(72%)和F1-Score(77%)等指标进行评估。 结果与讨论:ODSBahia-PTBR在翻译和分类OSDG数据集时实现了95%的准确率。结果显示了该模型在识别和分类与可持续发展目标一致的文本方面的有效性,特别是在跟踪所提议的可持续发展目标之间的交叉性方面具有重要意义。 研究意义:SDGbahia-PTBR模型通过为不同利益相关者提供一种创新工具来监测和分析与可持续发展目标一致的倡议,具有实际意义,有助于评估和促进2030议程。 原创性/价值:这项研究在将SDG 18、19和20纳入葡萄牙语文本分类器方面具有开创性,提供了一种前所未有且适用的方法,用于巴西和其他葡萄牙语国家的可持续监测。
AI理解论文
该文档主要探讨了如何利用自然语言处理(NLP)技术来支持可持续发展目标(SDGs)的实现,特别是在葡萄牙语文本的分类方面。以下是对该文档的详细总结:
研究背景与目标
背景:2015年,联合国成员国通过了2030年议程,该议程围绕17个可持续发展目标(SDGs)和169个相关目标展开,涵盖经济、社会和环境三个基本维度。然而,现有的17个SDGs未能充分涵盖一些特定的群体和问题,特别是在巴西和拉丁美洲的背景下。因此,研究者提出了三个新的目标:种族平等(SDG 18)、艺术、文化与传播(SDG 19)以及原住民和传统社区的权利(SDG 20)。
目标:本研究旨在提出一种方法,利用NLP技术客观地将葡萄牙语文本与SDGs相关联。具体目标包括:构建和验证一个多标签训练语料库,评估和比较不同预训练模型的性能,开发一个适用于葡萄牙语的文本分类模型ODSBahia-PTBR,并分析其性能。
理论框架
人工智能与自然语言处理:人工智能(AI)在社会中的应用日益广泛,特别是在知识表示和决策方面。自然语言处理(NLP)是AI的一个重要分支,旨在通过计算模型和过程解决理解人类语言的实际问题。NLP可以分为两大任务:自然语言理解(NLU)和自然语言生成(NLG)。
注意力机制模型:在NLP领域,注意力机制模型(如Transformer架构)在文本和语言处理任务中表现出色。该架构通过编码器-解码器结构处理输入序列,生成包含整个输入序列信息的中间表示。
方法
研究设计:本研究采用探索性、描述性和应用性的方法,结合定量分析和实验程序。研究中使用了三种预训练的葡萄牙语语言模型:Albertina PTBR、BERTimbau和DeBERTinha。通过调整这些模型以适应特定的多标签数据集,最终选择BERTimbau Base作为ODSBahia-PTBR模型的基础。
数据收集与分析:数据收集方法包括访谈、问卷调查和观察等。研究通过调整预训练模型来处理多标签数据集,并使用精确度、召回率和F1-Score等指标评估模型性能。
结果与讨论
模型性能:ODSBahia-PTBR模型在翻译和分类OSDG数据集时达到了95%的准确率,显示出在识别和分类与SDGs相关的文本方面的高效性。特别是在监测SDGs之间的交叉关系时,该模型表现出色。
讨论:研究结果表明,选择和调整预训练模型对于不同应用环境的适应性至关重要。未来的研究可以集中于优化特定标签的性能,扩展训练语料库,并探索新的数据源进行验证。
研究贡献与创新
实践意义:ODSBahia-PTBR为不同利益相关者提供了一种创新工具,用于监测和分析与SDGs对齐的举措,促进2030议程的评估和推广。
原创性与价值:该研究在葡萄牙语文本分类中首次引入了SDG 18、19和20,提供了一种新颖且适用于巴西及其他葡语国家的可持续监测方法。
结论
本研究不仅提出了一种将葡萄牙语文本与SDGs相关联的客观方法,还展示了适当选择和调整预训练模型的重要性。未来的研究可以进一步优化模型性能,扩展训练数据,并探索其他预训练模型的微调。
通过以上总结,读者可以全面理解该文档的内容、方法和贡献,特别是在利用NLP技术支持SDGs实现方面的创新和实践意义。