暂无数据
关于智能手机成瘾预测的机器学习方法的综合评审
原标题:A Comprehensive Review on Machine Learning Approaches for Smartphone Addiction Prediction
5 分
关键词
摘要
智能手机成瘾已成为一个紧迫的公共健康问题,对心理健康、社交互动和整体福祉产生深远影响。本研究提出了一种无监督机器学习框架,通过分析用户行为数据(如屏幕使用时间、应用程序使用模式和心理因素)来预测智能手机成瘾。该研究利用无监督学习技术识别未标记数据中的模式和共性,旨在无需预定义类别的情况下对有成瘾风险的个体进行分类。使用像TensorFlow和OpenCV这样的先进机器学习库,系统结合了一个稳健的流程,包括数据收集、预处理以及使用高性能模型进行训练和测试。研究结果强调,过度使用社交媒体和通知频率是重要的预测因素,其应用范围包括个性化干预计划、心理健康监测以及增强的家长控制系统。通过专注于可扩展和自适应的方法论,该框架不仅解决了智能手机成瘾的挑战,还为研究人员、政策制定者和应用开发者提供了宝贵的见解,以便在日益数字化的社会中设计出更健康的技术使用解决方案。 关键词:智能手机成瘾,机器学习,用户行为分析,心理健康,无监督学习。
AI理解论文
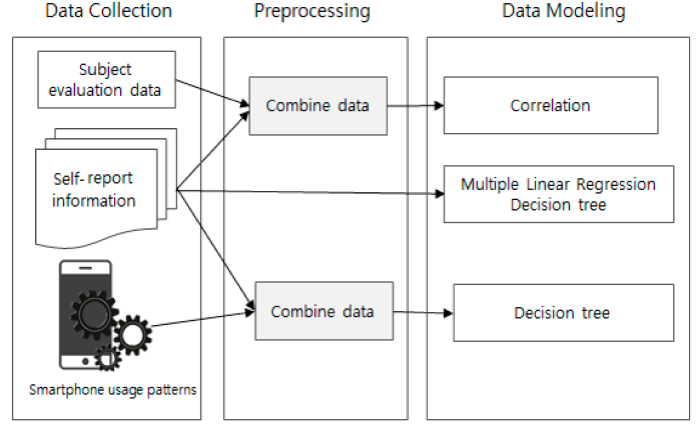
这篇论文主要探讨了智能手机成瘾预测的机器学习方法,旨在通过分析用户行为数据来识别有成瘾风险的个体。以下是对该文档的详细总结:
引言
智能手机的普及极大地改变了现代通信和生活方式,尤其是在印度,智能手机的渗透率达到了前所未有的水平。然而,这种普及也导致了智能手机成瘾的显著增加,这是一种行为现象,表现为对智能手机的过度和强迫性使用。尽管智能手机已融入日常生活,但其过度使用与多种负面影响相关,包括学业表现下降、心理健康恶化、生产力降低以及人际关系受损。
研究目标与问题定义
论文的主要目标是开发一种机器学习模型,能够分析使用模式并识别有成瘾风险的个体,从而实现有针对性的干预,减轻过度使用智能手机的负面影响。研究特别关注年轻人,尤其是大学生,因为他们是智能手机的主要用户群体。
方法与技术
论文中使用了多种机器学习模型来预测智能手机成瘾,包括堆叠分类器(Stacking Classifier)、CatBoost分类器和ExtraTrees分类器。这些模型通过分析用户的使用习惯和心理特征来预测成瘾风险。
- 堆叠分类器:通过结合多个基础学习器的预测结果,使用元学习器来提高模型性能,减少偏差。
- CatBoost分类器:以处理分类数据而闻名,使用梯度提升来提高性能。
- ExtraTrees分类器:采用生成多个决策树并聚合其预测的集成方法,表现出色,测试集上达到了完美的准确率。
数据处理与模型评估
数据在收集后会进行预处理,包括处理缺失值、编码分类变量以及数据缩放。目标属性是二元的,表示一个人是否成瘾。数据被分为训练集和测试集,用于训练和评估机器学习模型。ExtraTrees分类器在测试中表现最佳,达到了完美的准确率,成为系统最终预测的最合适选择。
系统实现
系统通过一个基于Web的平台提供交互式用户界面,使用HTML、CSS和JavaScript构建,Flask管理后端。用户可以输入数据、查看结果,并根据其成瘾风险获得个性化反馈。模型的预测结果可供医疗专业人员或应用开发者使用,以设计旨在减少智能手机成瘾的干预措施。
结论与贡献
该项目展示了如何使用机器学习方法识别有智能手机成瘾风险的人群。通过使用复杂的模型如ExtraTrees分类器,系统在预测成瘾倾向方面取得了高准确率。研究不仅加深了对智能手机成瘾的理解,还为更有效的解决方案和预防措施提供了可能性。
未来工作
未来研究的一个重要领域是扩大数据集,以包括更广泛和多样化的用户群体,可能包括来自不同人口群体和地理位置的数据。此外,添加来自智能手机传感器的实时数据(如屏幕时间、应用使用和社交媒体活动)可以提高系统的预测能力。通过整合更先进的机器学习方法,如深度学习算法,系统可以进一步改进,以更好地捕捉用户行为中的复杂模式,提高预测准确性。
文献综述
文献综述部分提到了多篇相关研究,探讨了不同的机器学习技术在智能手机成瘾预测中的应用。这些研究强调了特征选择的重要性以及数据收集方法的改进对提高模型性能的影响。
研究的局限性
研究的局限性包括:研究对象仅限于特定年龄组(15-25岁),数据收集依赖于自我报告,可能引入偏差或不准确性,研究未考虑所有可能影响智能手机成瘾的外部因素,如环境或社会经济影响。
通过这篇论文,研究人员希望为智能手机成瘾的预测和管理提供数据驱动的解决方案,帮助个人和社会更有效地管理智能手机的使用。