暂无数据
程度表达的第二语言学习:一种计算方法
原标题:Second language learning of degree expressions: A computational approach
5 分
关键词
摘要
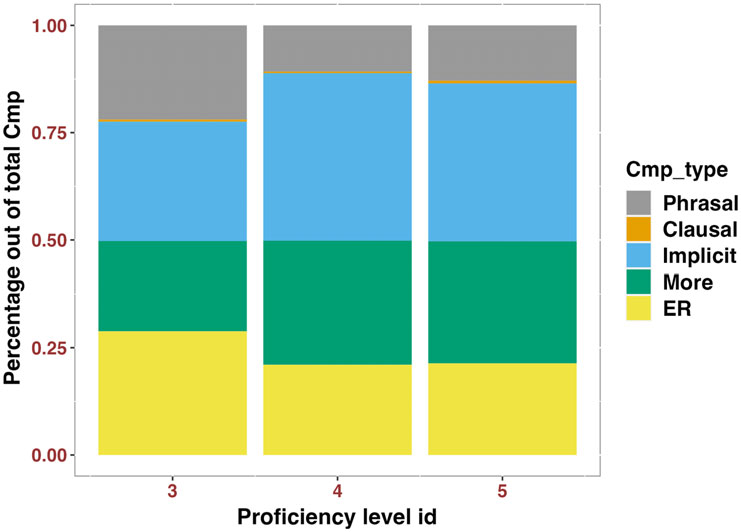
学位与实体或事件不同,它们指的是比较性质,并与可分级形容词(如“高”)密切相关。学位表达在二语(L2)研究中已被探讨,涵盖了可学性、母语(L1)迁移、对比分析和习得难度等领域。然而,在L2环境中学习学位表达的计算方法,特别是针对母语为中文的英语学习者,尚未得到充分研究。本研究旨在利用自然语言处理(NLP)方法填补这一空白,从大型语言模型(LLMs)的最新进展中汲取见解。本研究扩展了Cong(2024)的通用评估流程,专门分析学位表达,预测惊讶度指标将与L2学习者的熟练程度和不同发展阶段相关。关键是,我们通过整合基于频率的分析来解决惊讶度指标在捕捉二语发展中常见的使用不足或回避的局限性。使用Stanza开发的NLP流程,我们自动识别和分析学位表达,构建线性混合效应模型以跟踪L2发展轨迹。我们的研究结果表明,随着熟练程度的提高,学习者更频繁地使用复杂的学位表达,支持了将难度与可学性联系起来的理论。较高的惊讶度值与使用学位表达的较低熟练度相关,这些惊讶度比经典的NLP测量更能预测学位表达的熟练度。这些结果进一步证明了LLMs和NLP工具在L2发展中提供了有价值的见解,特别是在学位表达领域,扩展了以往的研究,并为理解L2学习过程提供了新方法。
AI理解论文
该文档主要探讨了**大语言模型(LLMs)在教育环境中应用的潜力,尤其是在评估语言学习者的语法复杂性和表达能力方面。研究的核心在于利用LLMs的惊讶度(surprisal)**指标来改进对语言学习者文本的自动评估。惊讶度是指在给定上下文中,某个词出现的意外程度,通常通过计算该词在上下文中的负对数概率来量化。
研究背景与动机
文档首先介绍了LLMs在自然语言处理(NLP)中的广泛应用,尤其是在语言学习和教育领域。随着LLMs的能力不断提升,它们在语言理解和生成方面表现出色,因此被认为可以用于改进语言学习者的评估工具。传统的语言评估方法依赖于手工标注和规则,而LLMs提供了一种数据驱动的替代方案。
方法与技术
研究采用了多种LLMs,包括DistilGPT2、GPT2、LLaMA2等,来计算文本的惊讶度。这些模型通过分析文本的词汇和句法结构,评估语言学习者在使用程度表达(degree expressions)时的熟练程度。研究还结合了传统的NLP指标,如句法复杂性(syntactic complexity),以评估LLMs的有效性。
惊讶度指标
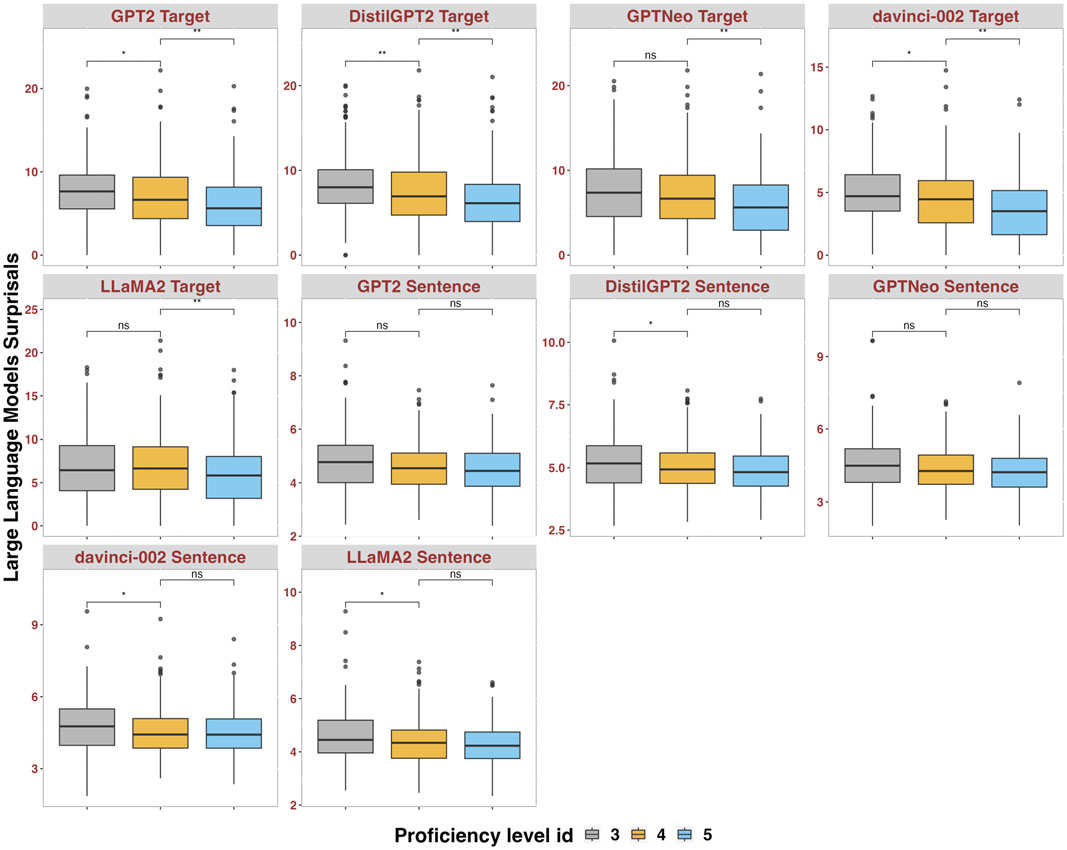
惊讶度指标用于量化文本中词汇和句子的意外程度。研究发现,随着语言学习者的熟练程度提高,文本的惊讶度值会降低,这表明学习者的表达变得更加流利和自然。研究还比较了LLMs的惊讶度指标与**概率上下文无关文法(PCFG)**惊讶度指标,发现LLMs的指标在评估语言学习者的熟练程度方面更具优势。
结果与分析
研究结果表明,LLMs的惊讶度指标在评估语言学习者的程度表达熟练度方面表现出色。通过随机森林模型的分析,发现LLMs的指标在决定性特征中占据前五位,显示出比传统指标更大的影响力。此外,研究还通过因子分析揭示了句法复杂性和文本长度与LLMs惊讶度之间的关系,表明长句和复杂句的使用与较高的语言熟练度相关。
因子分析
因子分析用于识别影响语言学习者表达能力的关键因素。研究识别出三个主要因子:句法复杂性、句子级别的LLMs惊讶度和文本长度、目标词汇的惊讶度。每个因子都揭示了不同的语言能力维度,表明LLMs惊讶度与传统句法复杂性指标捕捉了不同的表达熟练度方面。
贡献与意义
该研究的主要贡献在于展示了LLMs在语言学习评估中的潜力,特别是在自动化评估工具的开发中。通过结合LLMs的惊讶度指标,研究为提高语言学习者的评估准确性提供了新的视角。此外,研究还为未来的语言学习评估工具开发提供了理论基础,强调了数据驱动方法在教育技术中的应用。
结论
文档总结指出,LLMs的惊讶度指标在评估语言学习者的表达能力方面具有显著优势。随着LLMs技术的不断发展,它们在教育领域的应用前景广阔,尤其是在自动化评估和个性化学习路径的设计中。研究建议未来的工作可以进一步探索LLMs在不同语言学习场景中的应用,以验证其广泛适用性和有效性。
通过这项研究,作者为教育技术领域提供了新的工具和方法,展示了LLMs在提升语言学习评估质量方面的潜力。