暂无数据
车载光通信中uRLLC的5G NR编码和调制深度强化学习优化
原标题:5G NR Codes and Modulation Deep-RL Optimization for uRLLC in Vehicular OCC
5 分
关键词
摘要
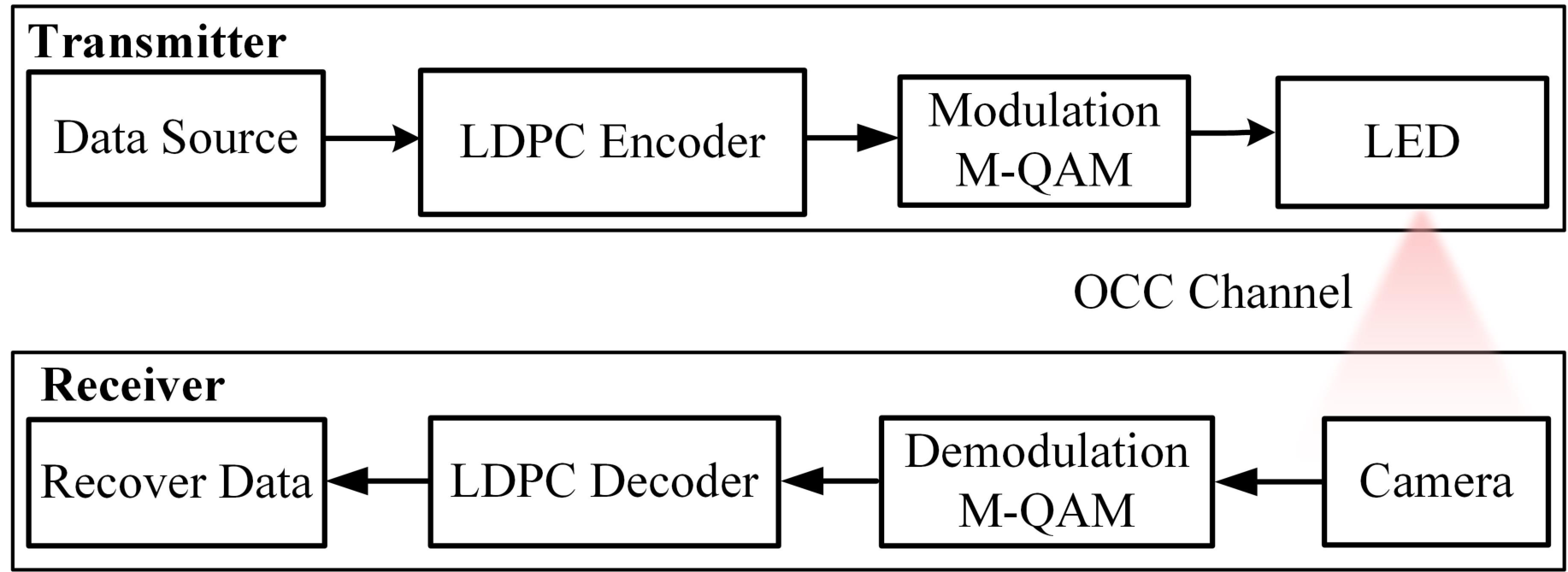
在动态和时变的车载网络中,现有的车载通信系统无法保证超可靠和低延迟通信(uRLLC)。为了解决这个问题,我们提出了一种新颖的基于深度强化学习的车载光学摄像机通信(OCC)系统,旨在最大化吞吐量并确保uRLLC。为此,我们的方案选择了多个车载链路的最佳编码率、调制方案和车辆速度。我们使用OCC作为无线电频率系统的替代方案,提供无干扰的通信。此外,我们采用5G新无线电低密度奇偶校验码和自适应调制方案,以支持可变速率和超高可靠性。所提出的大规模和连续性问题通过基于Wolpertinger架构的演员-评论家算法解决。我们对系统性能进行了广泛评估,并与文献中的几种其他方案以及我们方案的变体进行了比较。结果表明,所提出的方法在所有比较方案中实现了更高的平均吞吐量和更低的延迟。此外,所提出的方案能够满足uRLLC约束,而其他比较方案大多数情况下未能满足这些约束。
AI理解论文


该文档主要探讨了一种基于深度强化学习(DRL)的多智能体系统,用于在车载可见光通信(OCC)系统中实现超可靠低延迟通信(uRLLC)。以下是对该文档的详细总结:
研究背景与动机
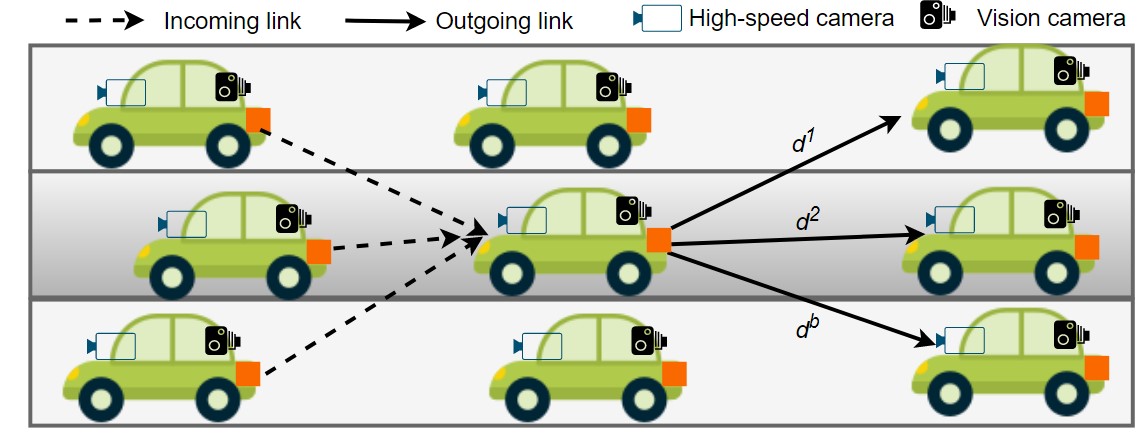
在动态的车载网络环境中,由于移动性和环境因素导致的信道变化,实现**超可靠低延迟通信(uRLLC)是一项具有挑战性的任务。传统的无线电频率(RF)技术在处理干扰和延迟方面存在局限性,而可见光通信(OCC)**系统能够更好地处理干扰问题。本文提出了一种去中心化的DRL方法,使每辆车能够基于直接的车间通信做出实时决策,从而提高通信速率并降低感知延迟。
方法与技术
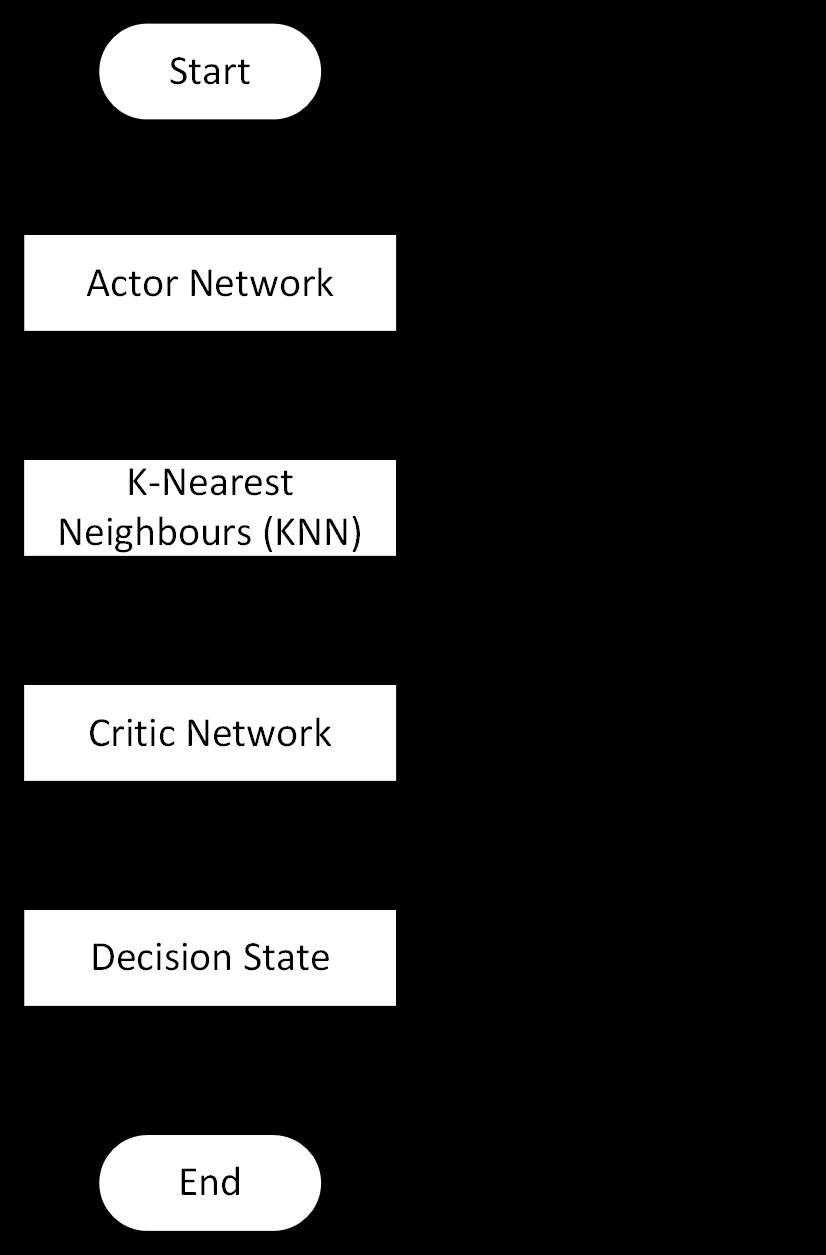
本文采用了深度确定性策略梯度(DDPG)算法的演员-评论家框架,并结合了Wolpertinger架构。这种架构能够有效处理大规模动作空间,避免在每个决策间隔中对所有可能动作进行评估的高计算成本。具体来说:
- 演员-评论家框架:通过两个神经网络(演员网络和评论家网络)分别负责策略生成和价值评估,能够有效解决连续状态-动作问题。
- Wolpertinger架构:通过评估最近邻的动作来减少计算成本,适用于大动作空间的场景。
模拟与训练
研究使用了SUMO(Simulation of Urban Mobility)框架进行仿真,该框架是一个多模型交通仿真器,支持多种交通场景的模拟。通过TraCI接口,DRL代理能够获取车辆网络的不同信息,如距离、速度、车辆位置等,并根据DRL代理找到的策略对环境进行操作。训练过程中,使用了均方根传播(RMSProp)优化器来最小化损失函数,并设置了不同的学习率以确保评论家网络比演员网络学习得更快。
结果与贡献
实验结果表明,所提出的方法在系统性能、误码率(BER)和延迟方面显著优于其他方案。具体贡献包括:
- 去中心化决策:每辆车能够基于直接的车间通信做出实时决策,无需服务器处理,从而保持最新的拓扑信息。
- 多链路优化:通过联合优化码率、调制和车辆速度,考虑多个车辆的状态,实现了uRLLC。
- 高效的动作空间处理:通过Wolpertinger架构有效处理大动作空间,避免了传统方法中计算复杂度高的问题。
复杂术语解释
- 深度强化学习(DRL):一种结合深度学习和强化学习的技术,用于解决复杂的决策问题。
- 演员-评论家框架:一种DRL架构,其中演员网络负责生成策略,评论家网络负责评估策略的价值。
- Wolpertinger架构:一种用于处理大动作空间的架构,通过评估最近邻的动作来减少计算成本。
- 均方根传播(RMSProp)优化器:一种用于优化神经网络的算法,通过调整学习率来加速收敛。
结论
本文提出的基于DRL的多智能体系统在车载OCC系统中实现了uRLLC,展示了其在动态环境中处理复杂决策问题的潜力。通过去中心化的决策和高效的动作空间处理,该方法在提高通信速率和降低延迟方面表现出色,为未来的车载通信系统提供了新的思路和方法。