就在Stable Cascade发布10天后,StabilityAI又发布了 Stable Diffusion 3 的早期预览版,这次SD3文生图模型的多主题提示(multi-subject prompts)、图像质量(image quality)和拼写能力(spelling abilities)都有了非常大的提升。SD3采用了和Sora同样的架构“diffusion transformer”,还引入了“flowmatching”,虽然官方并未发出详细的技术概要,但我们可以参考“Flow Matching for Generative Modeling”和“Scalable Diffusion Models with Transformers”的论文来了解下“diffusion transformer”和“flowmatching”到底是啥?形象的解释在文章结尾处。
下面我们来看看官方放出的示例图

Prompt: Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says "Stable Diffusion 3" made out of colorful energy提示词:史诗般的动漫艺术作品,一个巫师在夜晚的山顶上向黑暗的天空施放了一个宇宙咒语,上面写着“Stable Diffusion 3”,由五颜六色的能量制成

Prompt: a painting of an astronaut riding a pig wearing a tutu holding a pink umbrella, on the ground next to the pig is a robin bird wearing a top hat, in the corner are the words "stable diffusion”提示:一幅宇航员骑着一头穿着芭蕾舞短裙的猪,手里拿着一把粉红色的雨伞,猪旁边的地上是一只戴着礼帽的知更鸟,角落里是“stable diffusion”的字样

Prompt: studio photograph closeup of a chameleon over a black background提示:黑色背景上变色龙的工作室照片特写
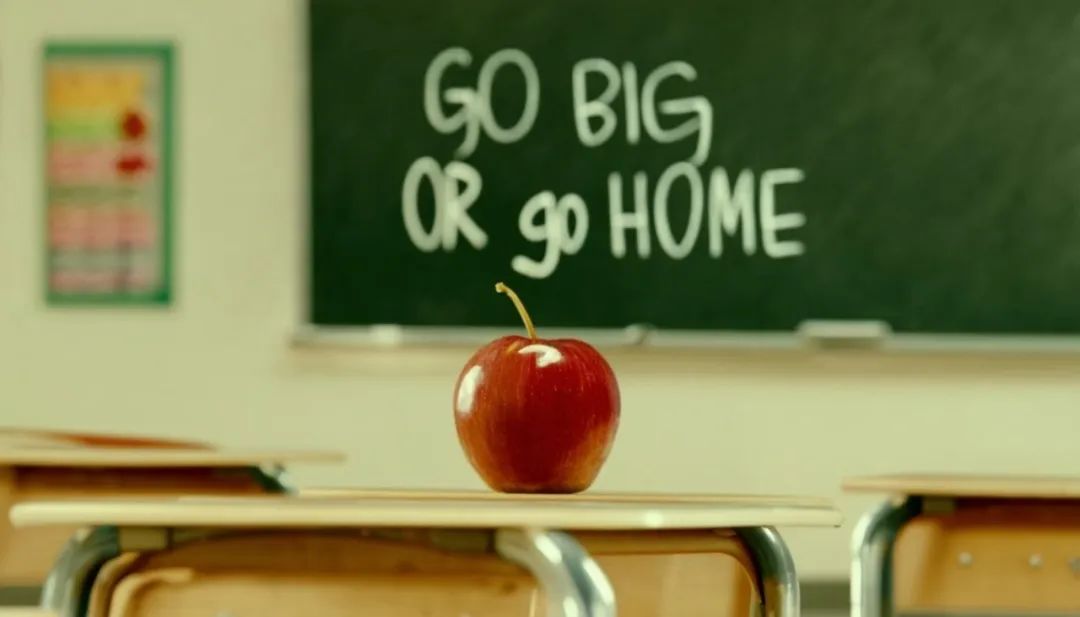
Prompt: cinematic photo of a red apple on a table in a classroom, on the blackboard are the words "go big or go home" written in chalk提示:教室桌子上红苹果的电影照片,黑板上用粉笔写着“go big or go home“的字样
以上是这些是官方放出的示例图,可以看出SD3理解提示词的能力将不再以“单词”为优,对于自然语言的理解也非常优秀。图像的质量相对于SDXL已经提升了非常多,甚至都不需要强调画面质量的提示词,最重要的是单词拼写能力已经能做到”我输入什么样的词,图像就生成什么样的词“。再者就是图像细节的处理也非常棒,不再是扭扭曲曲,不可名状之物了。
以下是网友放出的一些SD3成图:

Prompt: Three transparent glass bottles on a wooden table. The one on the left has red liquid and the number 1. The one in the middle has blue liquid and the number 2. The one on the right has green liquid and the number 3.提示:木桌上放着三个透明玻璃瓶。左边的那个是红色液体,数字是 1。中间的那个是蓝色液体,数字是 2。右边的那个是绿色液体,数字是 3。

Prompt: Photo of a red sphere on top of a blue cube. Behind them is a green triangle, on the right is a dog, on the left is a cat提示“蓝色立方体顶部的红色球体的照片。在他们身后是一个绿色的三角形,右边是一只狗,左边是一只猫”
接下来,我用同样的Prompt在DALLE3上做一下测试对比
(上图SD3,下图DALLE3)

Prompt: a painting of an astronaut riding a pig wearing a tutu holding a pink umbrella, on the ground next to the pig is a robin bird wearing a top hat, in the corner are the words "stable diffusion”提示:一幅宇航员骑着一头穿着芭蕾舞短裙的猪,手里拿着一把粉红色的雨伞,猪旁边的地上是一只戴着礼帽的知更鸟,角落里是“DALLE3”的字样

Prompt: Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says "DALLE3" made out of colorful energy提示词:史诗般的动漫艺术作品,一个巫师在夜晚的山顶上向黑暗的天空施放了一个宇宙咒语,上面写着“DALLE3”,由五颜六色的能量制成*


Prompt: studio photograph closeup of a chameleon over a black background 提示:黑色背景上变色龙的工作室照片特写
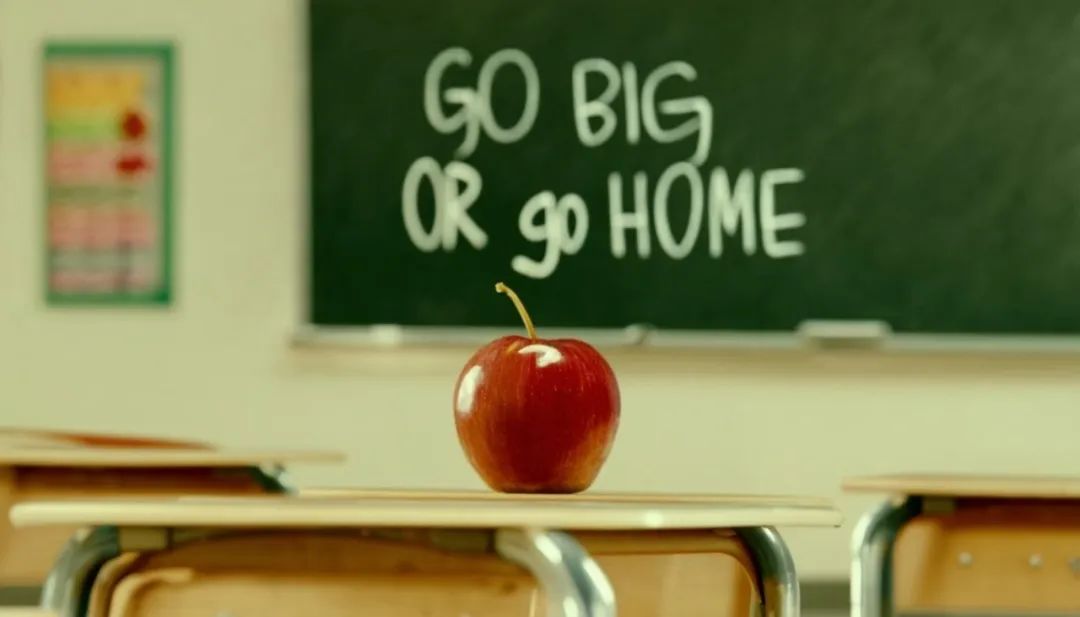

Prompt: cinematic photo of a red apple on a table in a classroom, on the blackboard are the words "go big or go home" written in chalk 提示:教室桌子上红苹果的电影照片,黑板上用粉笔写着“go big or go home“的字样


*Prompt: Three transparent glass bottles on a wooden table. The one on the left has red liquid and the number 1. The one in the middle has blue liquid and the number 2. The one on the right has green liquid and the number 3.提示:木桌上放着三个透明玻璃瓶。左边的那个是红色液体,数字是 1。中间的那个是蓝色液体,数字是 2。右边的那个是绿色液体,数字是 3。


*Prompt:* Photo of a red sphere on top of a blue cube. Behind them is a green triangle, on the right is a dog, on the left is a cat 提示“蓝色立方体顶部的红色球体的照片。在他们身后是一个绿色的三角形,右边是一只狗,左边是一只猫”
对于DALLE3生成的图小伙伴们怎么看,可以在留言区讨论噢,反正有几张图我是绷不住了。
目前,SD3还处于早期预览版,想要体验SD3的文生图能力,可以提交愿望单,申请通过后会以邮件的方式发到您申请的邮箱,在Discord服务器使用。
地址:https://stability.ai/stablediffusion3
以下是GPT4-0125-preview模型对于论文的理解:
参考“Flow Matching for Generative Modeling”论文

这篇论文提出了一种新的人工智能技术,用来生成图片。想象一下,我们有一堆随机的噪声数据,就像电视信号没有节目时的雪花点。我们的目标是把这些随机的噪声变成有意义的图片,比如人脸或者风景画。
以前的方法就像是慢慢地、一步步地把噪声变成图片,这个过程叫做“扩散模型”。但是这个过程比较慢,而且有时候不太稳定。就像你慢慢把一张纸从黑色涂成白色,希望最后能变成一幅画,但是这个过程可能会有瑕疵,而且需要很多时间。
具体来说,这个方法用了一种叫做“最优传输”的技术,它就像是找到了一条最直接的路径,让噪声数据直接变成我们想要的图片。这就像是在地图上找到了一条最短的路线,让你从起点直接到达目的地。
论文地址:https://arxiv.org/pdf/2210.02747.pdf
参考“Diffusion Transformers”论文

这篇论文介绍了一种名为扩散变换器(Diffusion Transformers,简称DiTs)的新型扩散模型,及其在图像生成领域的应用。DiTs基于一种叫做Transformer的神经网络架构。
想象一下,我们有一张模糊的图片,我们想要让它变得清晰和真实,就像用Photoshop一样。这个DiTs模型就像是有一个智能的橡皮擦,它可以逐步擦去图片上的噪声,最终生成一张高质量的图片。
具体来说,这个模型的训练过程就像是在玩一个逆向的游戏:它首先学习如何给图片添加噪声,然后学习如何逆向这个过程,把噪声去掉,恢复出清晰的图片。这个过程需要大量的计算,通过增加模型的计算量(用GFLOPs这个指标来衡量),发现可以让生成的图片质量变得更好,这里指的是U-Net。
论文中分析了模型大小、补丁大小和采样计算对DiTs性能的影响,特别强调了模型Gflops(十亿次浮点运算)在提高样本质量中的重要性。结果表明,扩大变换器骨架和增加模型Gflops可以显著提高视觉保真度。其中,DiT-XL/2模型被认为是最具计算效率的,并且在ImageNet基准测试中超越了之前所有的扩散模型。
此外,论文还讨论了除FID(Fréchet Inception Distance)之外的指标扩展影响、训练损失的扩展影响、VAE解码器的变体以及扩散U-Net模型复杂性等方面。
论文地址:https://arxiv.org/pdf/2212.09748.pdf
有兴趣读论文的小伙伴也可以自行阅读,无需魔法。
试试,新一代AI效率神器 @ 海鲸AI

