Qwen2是由阿里云通义千问团队开源的新一代大语言模型。该系列模型涵盖了从0.5B到72B不等的五个规模,在中文和英文基础上增加了27种语言的高质量数据,显著提升了模型的自然语言理解、代码编写、数学解题和多语言处理能力。Qwen2支持最长达128K tokens的上下文长度,优化了模型的泛化性和应用潜力。该系列模型在多个评测基准上表现优异,超越了Meta的Llama-3-70B,目前已在Hugging Face和ModelScope平台开源。

Qwen2的详细信息
| 模型名称 | 参数量 (B) | 非Embedding参数量 (B) | 是否使用GQA | 是否Tie Embedding | 上下文长度 (tokens) |
|---|---|---|---|---|---|
| Qwen2-0.5B | 0.49 | 0.35 | 是 | 是 | 32K |
| Qwen2-1.5B | 1.54 | 1.31 | 是 | 是 | 32K |
| Qwen2-7B | 7.07 | 5.98 | 是 | 否 | 128K |
| Qwen2-57B-A14B | 57.41 | 56.32 | 是 | 否 | 64K |
| Qwen2-72B-Instruct | 72.71 | 70.21 | 是 | 否 | 128K |
- 参数量:模型总的参数数量,以B(十亿)为单位。
- 非Embedding参数量:除去词嵌入(Embedding)部分的参数数量。
- 是否使用GQA:模型是否采用了GQA(Generalized Query Answering)技术。
- 是否Tie Embedding:模型是否使用了输入和输出层共享参数的技术。
- 上下文长度:模型能够处理的最大上下文长度,以tokens为单位。
Qwen2的官网入口
- 官方博客介绍:https://qwenlm.github.io/zh/blog/qwen2/
- GitHub地址:https://github.com/QwenLM/Qwen2
- Hugging Face地址:https://huggingface.co/Qwen
- ModelScope地址:https://modelscope.cn/organization/qwen
- Hugging Face在线Demo:https://huggingface.co/spaces/Qwen/Qwen2-72B-Instruct
Qwen2的模型评测
Qwen2系列在多个评测基准上表现出色,特别是在Qwen2-72B模型上,实现了大幅度的效果提升。在自然语言理解、知识、代码、数学和多语言等多项能力上,Qwen2-72B显著超越了当前领先的模型,如Llama-3-70B和Qwen1.5的110B模型。在16个基准测试中,Qwen2-72B-Instruct展现了在基础能力和对齐人类价值观方面的平衡,超越了Qwen1.5的72B模型,并与Llama-3-70B-Instruct相匹敌。
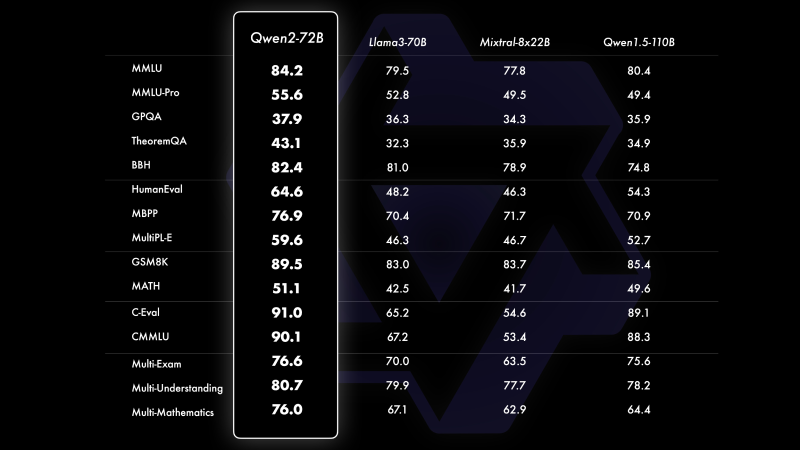
Qwen2的性能亮点
- 代码与数学能力:Qwen2在代码和数学方面的能力显著提升,成功融合了CodeQwen1.5的经验,并在多种编程语言上实现效果提升。数学能力通过大规模高质量数据支持,实现了解题能力的飞跃。
- 长文本处理:Qwen2系列的Instruct模型在32K上下文长度上训练,并通过技术如YARN扩展至更长上下文,Qwen2-72B-Instruct能完美处理128K上下文长度的信息抽取任务。
- 安全性:在多语言不安全查询类别中,Qwen2-72B-Instruct在安全性方面与GPT-4相当,且显著优于Mistral-8x22B模型,减少了生成有害响应的比例。
- 多语言能力:Qwen2在多语言评测中表现优异,增强了27种语言的处理能力,并优化了语言转换问题,降低了模型发生语言转换的概率。

Qwen2不仅在技术上取得了突破,还在实际应用中展现了强大的潜力。通过优化模型的泛化性和应用潜力,Qwen2系列为自然语言处理领域带来了新的可能性。无论是在代码编写、数学解题,还是在多语言处理方面,Qwen2都展现了卓越的性能,成为了当前大语言模型中的佼佼者。
试试,新一代AI效率神器 @ 海鲸AI

